링크 1. Overview & IDEA - HW monitoring 2. Problem & PoC 3. DATA Design 4. Publisher 5. Database & logger 6. Visualization 7. ToBeContinue…?
Overview
내가생각하는 Data Engineering

Data Engineering을 공부하게 되면서 이걸로 도대체 뭘 할 수 있을까 하는 생각이 굉장히 많이 들었다. 결국 Data Engineering은 의사결정을 수치적인 근거로 할 수 있도록 데이터를 가공, 적제하는 Pip Line을 만들어주는 것 이라고 생각한다. 결국 AI도 큰 틀에서 본다면 수 많은 데이터를 가지고 이를 가공해서 모델이 학습 시킬 수 있도록 정리한 후 모델을 훈련시켜 여러가지 문제를 푸는 알고리즘에 불과하다고 생각한다.
IDEA
문제는 공부를 하면서 도대체 어떻게 공부해야 실제 환경과 비슷한 상황을 만들 수 있을까 였다.
학회에서는 한창 AI가 대두되는 상황이었고 지금도 마찬가지이지만, 그당시 Kaggle에서온 많은 데이터로 공부를 했었다. 하지만 생각해보면 해당 데이터들은 어느정도 가공이 된 상황이고 이러한 데이터들은 pip line은 커녕 그냥 분석만 가능하게 해서 내마음에 들지 않는다.

머리 속에 든 생각은 불편한 점을 한번 고쳐보자였다. 단 문제는 아래와 같은 성격을 가지고 있어야 했다.
- 항상 데이터가 살아서 들어와야 한다.
- pip line을 만들기 위해서는 마치 사람 심장처럼 움직이는 가변적인 데이터를 끊임없이 받아야한다.
- 내가 언제든지 생산할 수 데이터여야한다.
- 데이터를 생성하는 면에서 제약이 있다면 문제는 언제 데이터가 들어올지 모르고 의미가 사라진다.
- 돈이 많이 들지 않아야 한다.
- 밑에서 소개하겠지만 남에 뭔가를 빌려서 할 때는 항상 보안에 유의해야한다… 내가 Security1. Security Config & Filter를 꽤 열심히 공부한 이유도 이거 때문이다…
경험중에 과거 Hadoop cluster를 구축해 보겠다고 AWS에서 EC2를 6대정도 빌려서 Master Node, Secondary Node, Slave Nodes로 해서 운영을 해봤다. 그 당시 스타벅스에서 spark로 RDD공부를 좀 하고 있던 상황이었는데, Network이슈가 있었는지 local에서 제출한 job이 실행되지 않고 Network Error가 떳다 😵💫
일딴 당황했지만 침착하게 와이파이를 다시 켜보고 해도 작동이 잘안되더라… 해서 AWS에서 하둡 PORT를 모든 IP에 대해서 개방한 기억이 있다. 이게 근본적인 원인인지는 몰라도 갑자기 gamil이 따룽따룽 거리면서 연락이 엄청 와있었다.
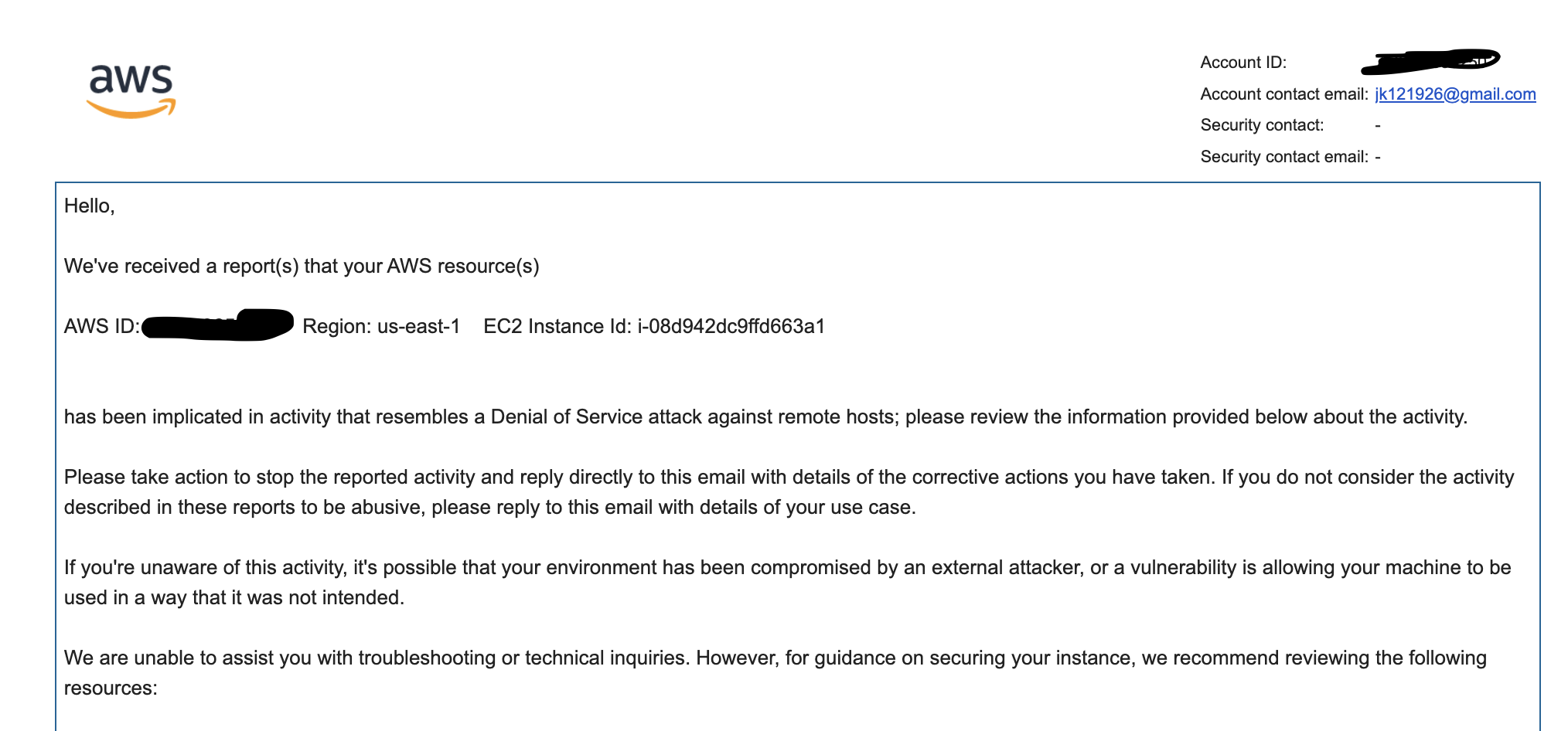
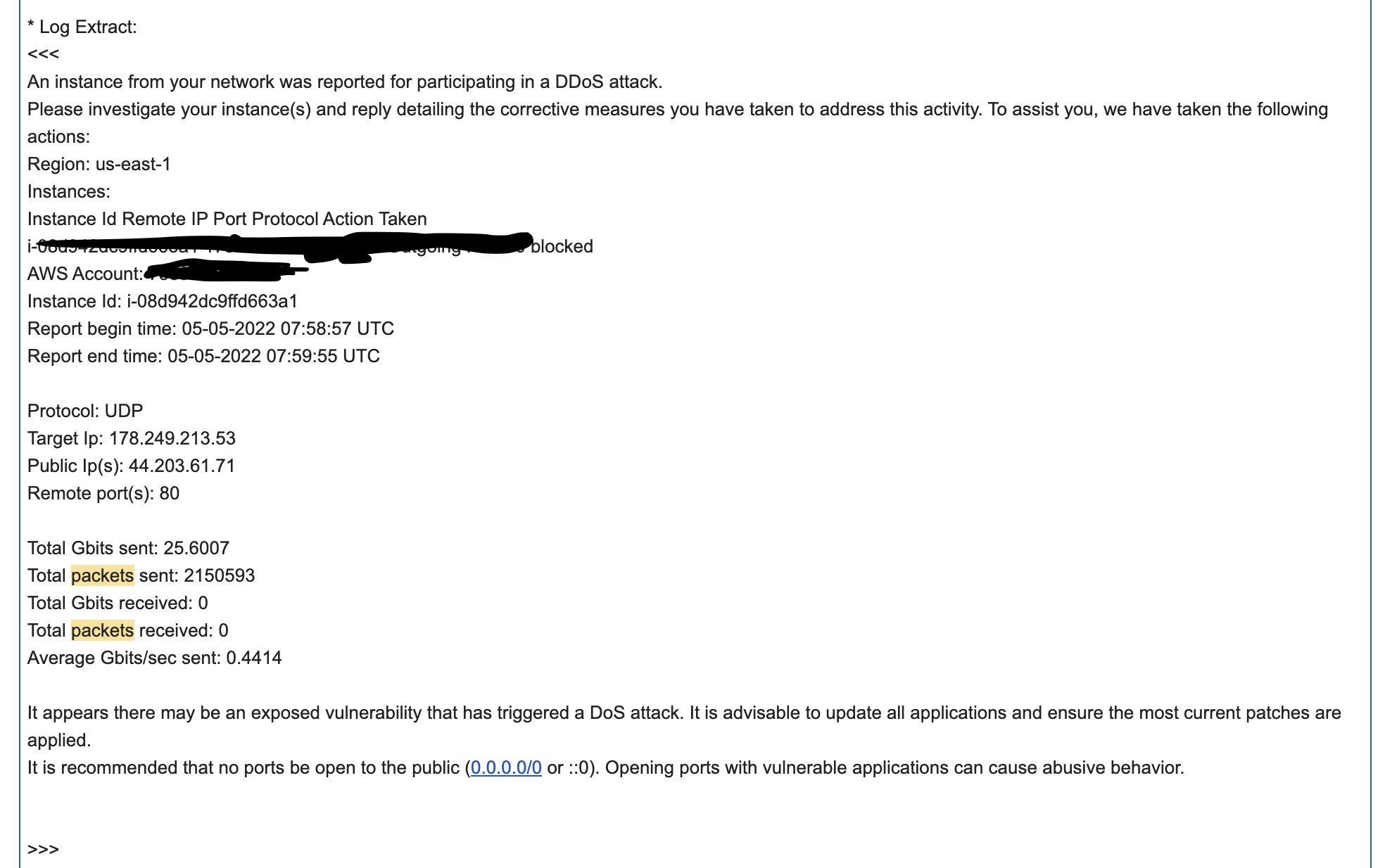 살면서 이런거 처음 받아봤다… DoS공격을 받았다는 건데, 순간 AWS에서 1000만원이 나간다라는 글을 본적이있고 나는 이런거 없겠지 하면서 안심했던 기억이 스쳐지나가며 많은 생각이 들었다…
수중에 50만원도 없었던 시절이었는데…
살면서 이런거 처음 받아봤다… DoS공격을 받았다는 건데, 순간 AWS에서 1000만원이 나간다라는 글을 본적이있고 나는 이런거 없겠지 하면서 안심했던 기억이 스쳐지나가며 많은 생각이 들었다…
수중에 50만원도 없었던 시절이었는데…

결과적으로는 모든 instance를 삭제하면 일딴 된다는 말에 몇일 밤새면서 만든 모든 Node를 삭제하고 나중에 bill을 받아봤더니 그 잠깐 털린걸로 8만원이나 요금이 나왔던 기억이 있다…
아직 생각만해도 아찔한데 여기서 idea를 생각해 내게 되었는데, 내가 만약 cluster에서 문제가 생기는 상황임을 미리 알 수 있다면 내 피같은 돈을 아낄 수 있었을 텐데… 라는 생각에게임하면서 썻던 CPU, MEM, Grapic Card 모니터링 프로그램을 AWS에 달면 댕 좋겠네 라는 생각에 이르른다.
->다음편2. Problem & PoC에서 계속