Introduction
해당 논문이 등장하게 된 간단한 배경은 다음과 같다.
최근에 많은 논문들에서 경험적으로 실험한 부분을 이야기 해보면 굉장히 다양한 깊이, 넓이, input image의 resolution을 다양하게 조합해 최적의 결과를 찾아내려고 한다. 해당 논문에서는 이러한 과정을 scaling이라고 표현하는데, 이러한 scaling과정을 좀 정량적으로? 방법론적으로 정립을 해놓으면 좀 잘 찾을 수 있지 않나? 라는 생각에서 출발한 논문 같다.
튜닝을 하는 보통의 요소는 다음과 같다.
- deep → layer가 쌓여지는 깊이를 의미한다. 5~6년 정도의 실험적 결과로 비추어 보아 deep가 깊을 수록 더정확성이 높은 것을 볼 수있다.
- width → 같은 deep에 여러 layer를 겹쳐서 운용하게 되면 같은 위계상에서 다른 feature를 볼 수있게 됨으로 tunning을 하는데 중요한 요소가 된다.
- input image resolution or size → input image는 어떤 해상도를 가지느냐 혹은 어떤 크기를 가지느냐에 따라서 다른 결과를 낼 수 있다고 한다.
직관적으로 보게 된다면 셋중에 하나의 요인만 가지고 모델을 만드는 것 보다 세가지를 적절하게 홉합하여 모델을 만드는 것이 좀 더 유리한 방법으로 이해 된다.
만약 input image가 커진다면 network는 더 많은 레이어를 필요로 하게되고 더 많은 channel을 가지게 됨으로 파라미터도 많아짐을 의미할 수 있다.
따라서 이러한 관계의 적절성을 찾아내는 것이 이 논문의 주요 골자이며 논문에서는 이러한 방법을 baseline이라고 정하고 실험했으며 결과적으로는 GPipe에 6.1배 빠른 학습 속도와 8.4배 적은 파라미터를 가지고 더 높은 정확성을 가지는 모델을 만들어냈다고 한다.
RelatedWork
-
ConvNet Accuracy
이전에 나온 CNN은 대부분 깊이와 넓이를 늘려가면서 지속적으로 발전해 왔다. alexNet → GoogleNet → SENet → GPipe 같은 논문들이 등장했지만 여전히 resource에대한 한정성 덕분에 다른 튜닝방법을 찾고 있는 실정이었다.
-
ConvNet Efficiency
이러한 CNN모델의 정확성은 moblieNet과 같은 소형 device에 적합한 모델을 만들 때 튜닝을 했지만 resource가 많은 상황일 때 어떻게 학습해야 하는지는 아직 연구 되고 있지 않았다. 이러한 이유로 해당 논문에서는 super large한 resource를 가지고 있을 때 어떻게 학습해야 되는지에 대해서 논의 해 보고자한다.
-
Model scaling
ResNet은 전체 layer의 깊이를 어떻게 조절하는지에 따른 성능을 측정하였고 mobileNet은 width에 따른 성능을 FLOPS는 image의 size에 대한 성능을 측정하였다. 해당 논문에서는 이러한 세가지 paramemter를 어떻게 튜닝하는지에 대한 체계적인 process를 정립해나간다.
Compound Model Scaling
-
problem formulation
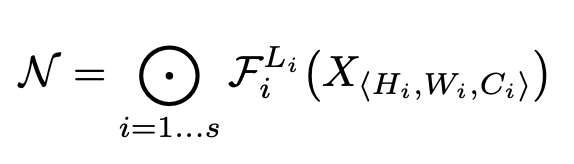
문제를 정의하기 위해서는 우선 위의 수식을 이해해야한다.
Fi는 operation factor이고 X는 input layer dimension Hi는 input hight, Wi는 input weight, Ci는 input Channel, Li는 반복되는 L번째 레이어라고 할 수 있다. 해서 해당 수식은 input으로 H,W,C가 주어졌을 때 반복되는 L번째 레이어에 F operation을 모두 더한 값을 ConvNet N이라고 지정하는 것이다.
여기까지 오면 이해를 하나 해야되는 것은 차원이 줄어들 수록 H,W가 줄어들 수록 C가 늘어난 다는 점을 이해하고 보자.
이전 모델들에서는 best Architecture 즉 최적의 operate function을 찾는데 집중했다면 해당 모델은 function은 내버려 두고 Network의 deep (L)과 H,W을 기준으로 모델의 baseline을 잡아준다. 그리고 해당 모델이 굉장히 차원이 큰 상황에도 적용할 수 있게 하려면 어떤 scaling factor를 정해 놓아야 한다고 말한다. 이러한 scaling factor는 각 d,w,r로 표현되며 최대 정확성을 3개의 파라미터로 나타내는 식이 될 수 있다.
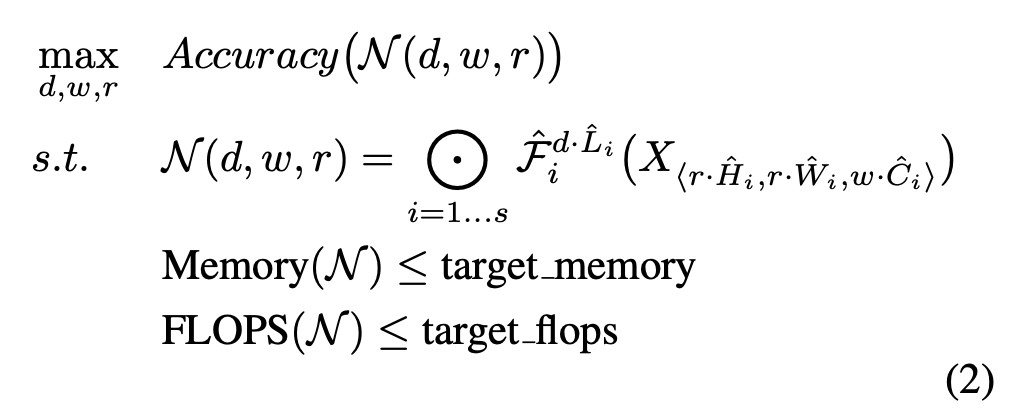
-
Scaling dimensions
해당 절에서는 scaling하는 대상에 대해서 이야기한다.
-
Depth
네트워크의 깊이를 나타내는데 직관적으로 깊을 수록 더 좋은 성능을 낸다고 이야기한다. 하지만 너무 깊게 된다면 vanishing gradient문제를 가질 수 있게 됨으로 주의를 요한다.
-
Width
깊이가 깊어 지기 힘든 모델에 사용한다. 다만 너무 얕은 모델에는 high demension feature를 뽑아낼 수 없기 때문에 문제가 될 수 있다.
-
Resolution
이미지의 크기는 해상도가 높을 수록 크기가 클수록 더 좋은 정확성을 내지만 크기가 클수록 채널수가 많아지는 단점이 있어 이를 확인해야한다.
-
-
Compound Scaling
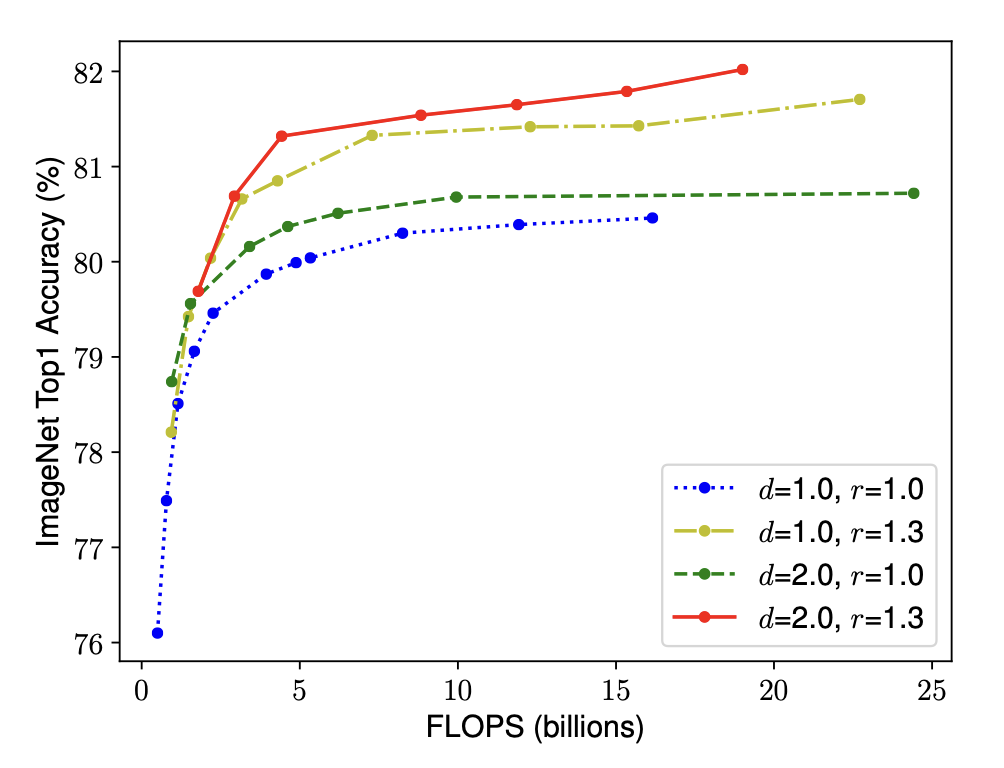
이 절에서 이야기 하고 싶었던 것은 결국 세개의 parameter를 적절하게 조합할 수 있어야 더 좋은 성능을 낼 수 있다는 이야기를 하고 싶은 것이다. 같은 width일 때 d와 r을 적절하게 조합할 수 있다면 더욱 좋은 정확성을 낼 수 있다는 이야기를 한다.
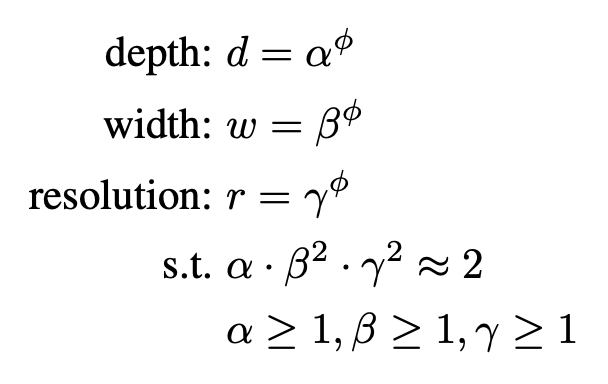
결과적으로는 이러한 세개의 파라미터를 튜닝하는 한가지 factor를 제시하게 된다. 보이는 것처럼 a * b^2 * r^2값이 근사 2가 되게 만들고 각각의 값은 1보다 크며 이를 만족하는 pi값중에서 최적의 값을 잡아내는 것을 목표로한다.
a,b,r는 간단한 grid search를 통해서 찾아내게 된다.
근사 2가 되게하는 이유는 FLOPS에서 2배로 뭔가 커지면 4배의 연산량이 사용되야 하기 때문에 이를 제한하기 위해서 2를 사용한 것으로 보인다.
EfficientNet Architecture
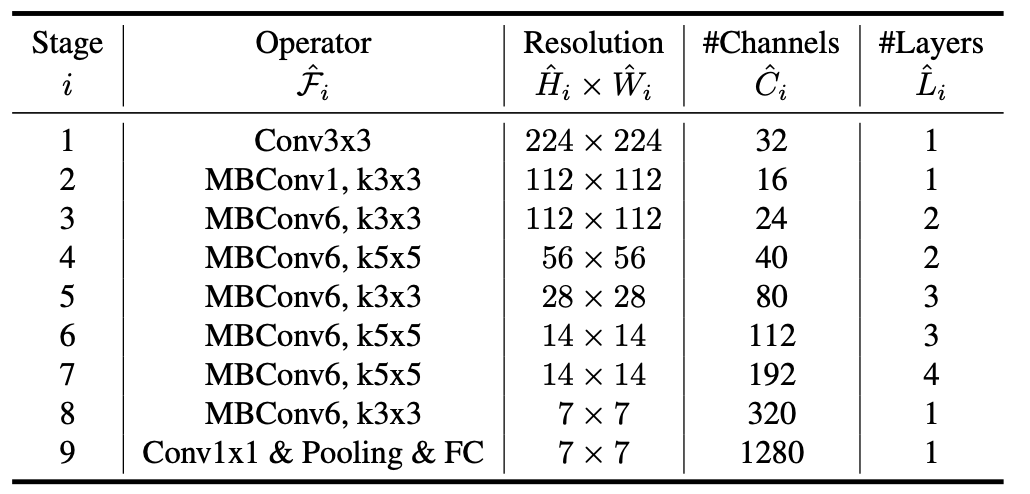
해당절에서 가장이야기 하고 싶었던 부분은 FLOPS를 특정값에 맞추지 않고 연산을 진행해도 효율적인 base line을 만들어야 한다는 것이 이야기하는 것 같다.
FLOPS란 floating point operations per second로 1초동안 컴퓨터가 수행할 수 있는 부동소수점연산이다. 따러서 정확성과 해당 컴퓨터의 컴퓨팅성능을 위해 여러 파라미터를 잡았고 이는 MBConvNet???과 유사함을 보여서 이를 기본 모델로 잡는다.
또 첫번째로 pi를 1로 잡고 grid search를 통해서 a,b,r의 값을 알아낸다.
이후 두번째로는 a,b,r를 고정해놓고 pi를 바꿔가면서 값을 변화시켜 보는 것이다.
Experiment
좋았다?
이부분은 차라리 모델을 구현할 때 다시 읽어보면 좋을 것 같은게 굳이 논문 설명에 hyperparameter같은 작은 부분들을 집어 놓느니 차라리 필요할 때 다시 읽어 보는 것이 좋을 것 같다.
결과적으로는 compoun scaling을 진행할 때 훨신 쫗은 결과를 가져올 수 있다고 이야기한다.
Discussion & Conslusion
결과적으로 compound scaling이라는 기법은 모델에서 최대의 효율로 최대의 정확성을 내는 baseline을 정량적으로 찾아낼 수 있는 과정을 찾아낼 수 있는 것이라고 이해할 수 있다.