1. Overview & IDEA - HW monitoring 2. Problem & PoC 3. DATA Design 4. Publisher 5. Database & logger 6. Visualization 7. ToBeContinue…?
다왔다!!!! 우어어어어어어!

influxDB visualization
앞부분까지 끝냈다면? influxdb에 자체적으로 query를 gui로 하게 해주고 dashboard를 만들어주는 기능이 있긴하다.
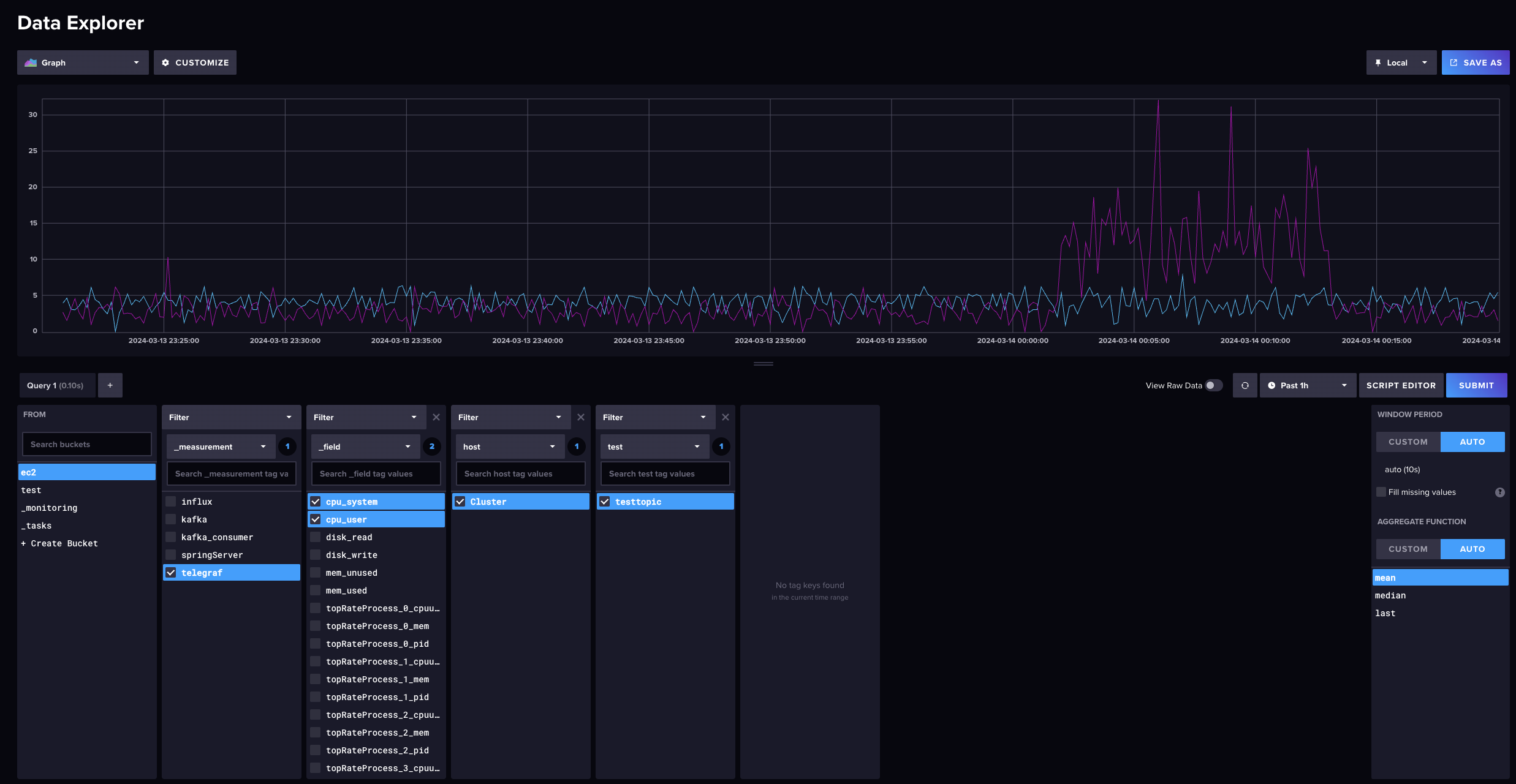 요렇게 만들어 주기도 하는데 문제는 실시간 모니터링이 되지 않는 다는 것이다. 내가 원하는건 모니터에 띄워놨다가 문제가 생기면 바로 볼 수 있는 구조인데 이친구는 단일 쿼리를 날리는 것처럼 한번 submit하면 한번밖에 나오지 않는다. 해서 grafana를 선택해서 만드는 것이다.
사실 influxdb로 해도 시각화는 꽤 된다.
요렇게 만들어 주기도 하는데 문제는 실시간 모니터링이 되지 않는 다는 것이다. 내가 원하는건 모니터에 띄워놨다가 문제가 생기면 바로 볼 수 있는 구조인데 이친구는 단일 쿼리를 날리는 것처럼 한번 submit하면 한번밖에 나오지 않는다. 해서 grafana를 선택해서 만드는 것이다.
사실 influxdb로 해도 시각화는 꽤 된다.
Grafana
시간이 좀더 있다면 따로 이런 프로그램에 대해서 장단점을 남겨보는 것도 좋은 방법일 것 같다.
설치
Grafana설치가 젤어려웠다. 뭘이렇게 깔아야되는게 많았는지…
grafana document https://grafana.com/docs/grafana/latest/setup-grafana/installation/debian/ grafana download url https://grafana.com/grafana/download?platform=arm&edition=oss
sudo apt-get install -y adduser libfontconfig1
# grafana 다운로드
wget https://dl.grafana.com/oss/release/grafana_7.5.2_amd64.deb
# grafana 설치
sudo dpkg -i grafana_7.5.2_amd64.deb
# 실행
sudo service grafana-server start
# 실행 상태 확인
sudo service grafana-server status
document에는 굉장히 걸 해야했다. 잘 이해가 안되긴 하지만 GPG 이런것도 해야했는데 잘 모르겠어서 우선 블로그에 있는 방식을 찾아서 정리를 했다.
현재 나온 버전은 10.4.0까지 나온 것 같은데 우선 위에 코드 처럼 7.5.2로 진행을 했다
요렇게 설치를 하게 되고 실행을 하게 되면 3000 port를 열어줘야한다.
그렇게 되면 아래 화면이 나온다.
여기서 이제 Source DataBase를 설정해줘야 한다.
Source DataBases 설정
위 이미지에 두번째 네모에 “ADD your first data source”를 누르면 아래 창으로 넘어간다.
 요기서 많은 걸 쓸 수 있다. 참 좋아진거 같아 ㅋㅋㅋㅋ InfluxDB를 선택해준다.
요기서 많은 걸 쓸 수 있다. 참 좋아진거 같아 ㅋㅋㅋㅋ InfluxDB를 선택해준다.
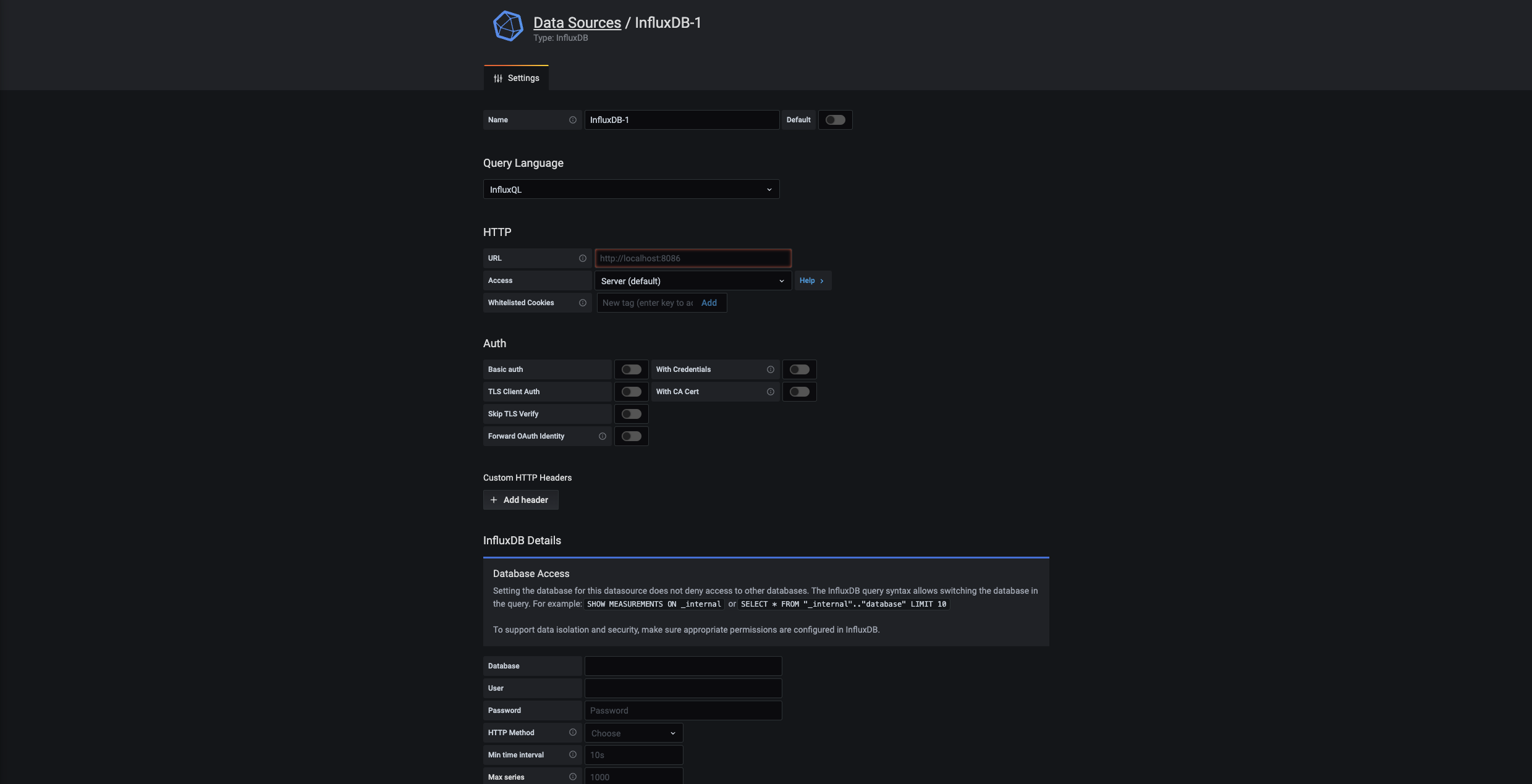 요런 창이 나오게 되는데 설정은 아래와 같다.
요런 창이 나오게 되는데 설정은 아래와 같다.
- Name : DataSource이름이다.
- Query Language : 이부분은 InfluxQL과 Flux가 있는데 Influxdb가 2.x.x버전이라면 Flux를 선택해 줘야한다.
- HTTP :
- url : influxdb ip:port 를 넣어준다.
- Access : Server
- Auth : 일딴 아무것도 하지 않았다. 사실 카프카에도 ssh설정을 해주고 다 보안을 적용해 줘야 하지만 일딴은 plaintext로 진행했다.
- InfluxDB Details
- Query Language가 InfluxQL로 되어있으면 User, Password로 인증을 하게 되어있는데 2.x.x는 이전에 받은 5. Database & logger에 Token을 넣는 Token을 넣게 되어있다.
- Organization : influxdb에 넣은 organization
- Default Bucket : influxdb에서 설정한 bucket 혹은 데이터를 가져오고 싶은 bucket을 넣으면 된다.
이후 Save&Test해봤을 때 옆에 초록색이나오면 OK! 이러면 이제 DashBoard로 갈 수 있다.
DashBoard
대시보드는 결국 정해진 쿼리를 날려서 해당시점에 집계된 데이터들을 보여주는 것이기 때문에 Influxdb의 쿼리를 넣으면 이게 실시간으로 렌더링 되는 것과 같게 나는 이해를 하고 있다.
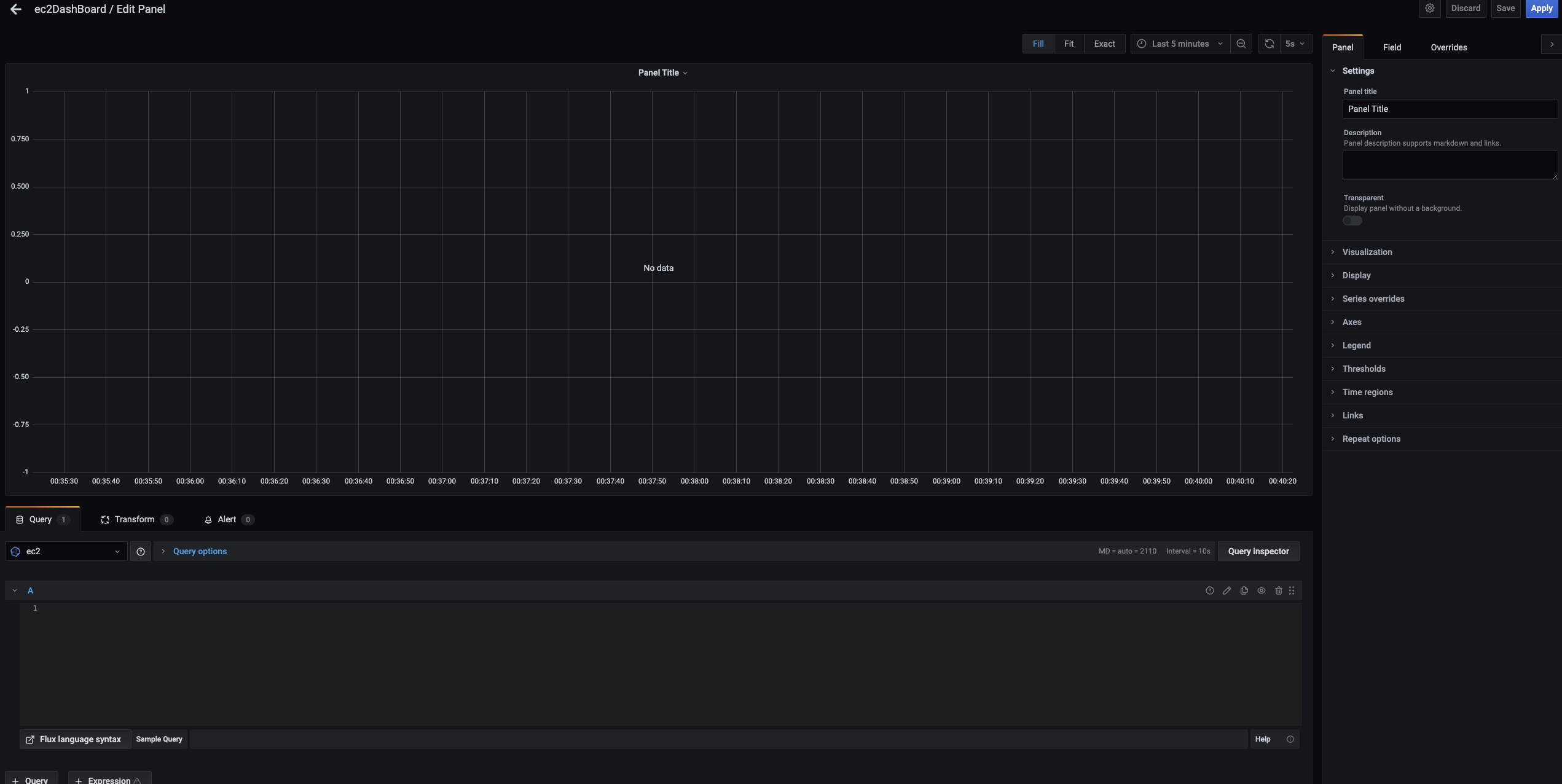
여기 밑부분에 보면 query를 입력하는 부분이 있다. 여기에 뭘 어떻게 넣지? 가 고민이었는데… influxdb를 좀 편하게 쓸 줄 알면 다양한 것도 해봤겠지만 influxdb에서 제공하는 쿼리를 넣어도 충분히 시각화를 진행할 수 있다.
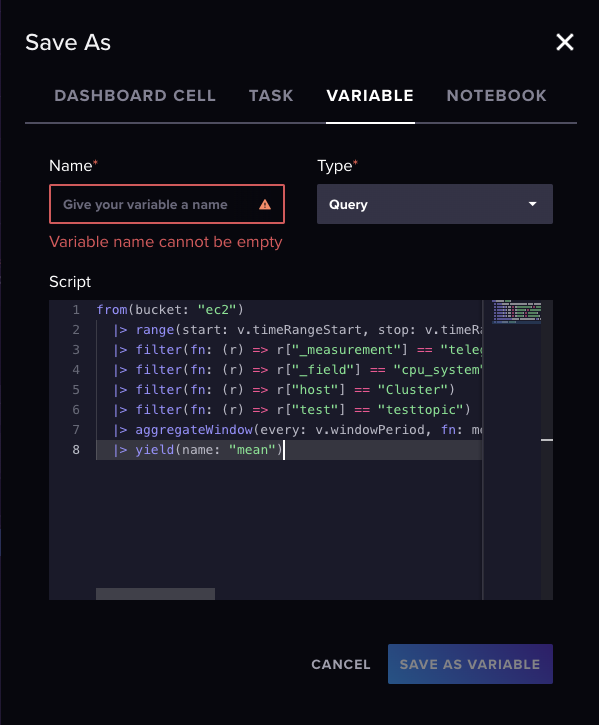 influxdb에서 제공하는 save as에서 variable 탭으로 가보면 현재 렌더링 되는 시각화 그래프의 쿼리가 모두 나타나있다. 요부분을 복사해서 grafana에 던져주면 끝!!!
influxdb에서 제공하는 save as에서 variable 탭으로 가보면 현재 렌더링 되는 시각화 그래프의 쿼리가 모두 나타나있다. 요부분을 복사해서 grafana에 던져주면 끝!!!
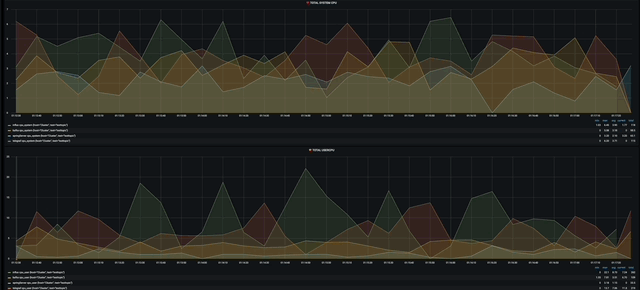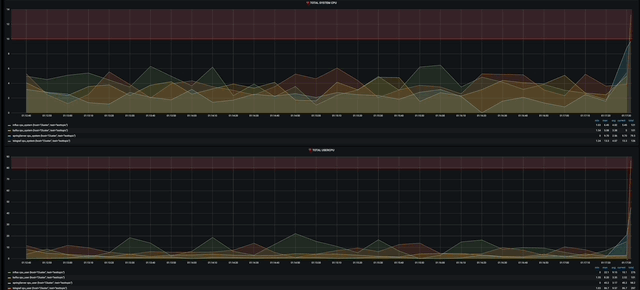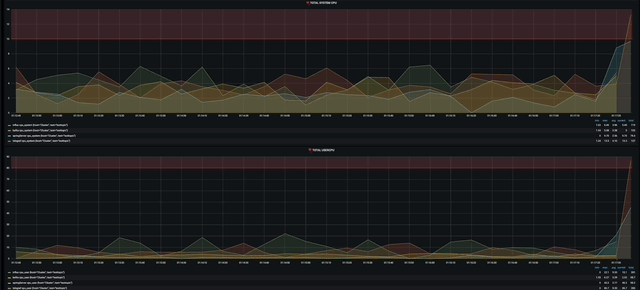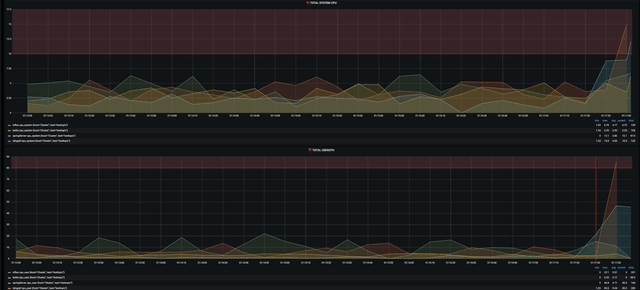
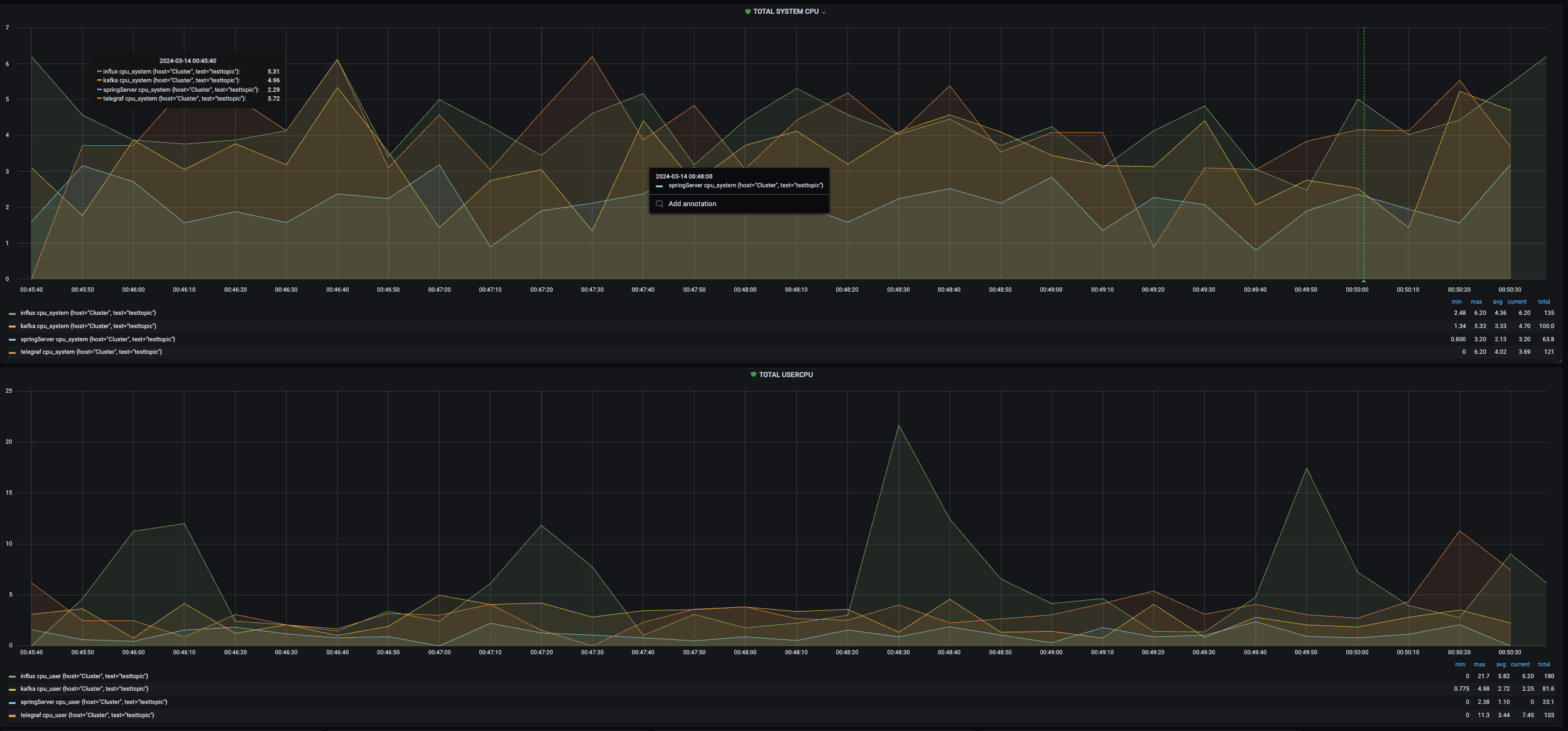 첫번째는 Total System cpu와 User cpu를 현재 가용중인 모든 서버를 대상으로 시각화 해놓았다.
작게 보이지만 influxdb가 가장 많이 사용되고 그다음으로 telegraf 그리고 grafana순으로 사용되고 있을 것이다.
첫번째는 Total System cpu와 User cpu를 현재 가용중인 모든 서버를 대상으로 시각화 해놓았다.
작게 보이지만 influxdb가 가장 많이 사용되고 그다음으로 telegraf 그리고 grafana순으로 사용되고 있을 것이다.
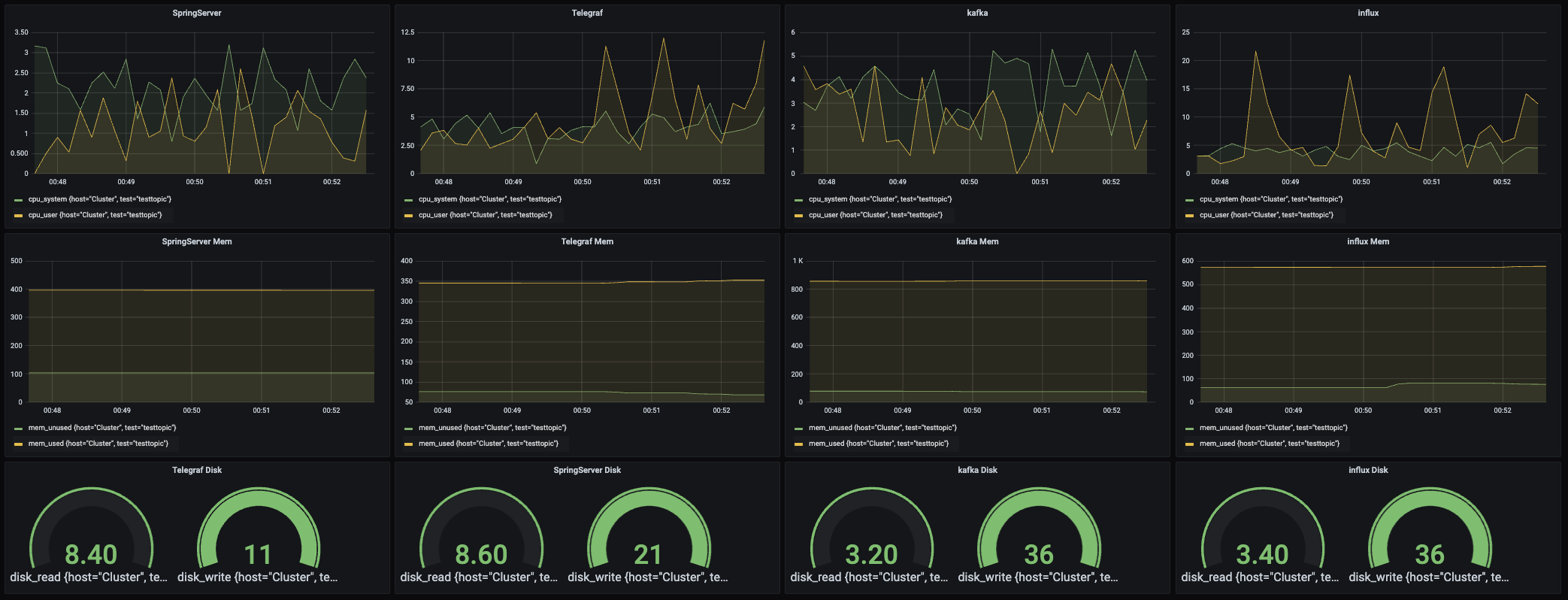 다음으로는 서버마다 cpu, memory, dist write/read를 시각화 해 놓았다. 너무 뿌듯하다 ㅋㅋㅋㅋ
다음으로는 서버마다 cpu, memory, dist write/read를 시각화 해 놓았다. 너무 뿌듯하다 ㅋㅋㅋㅋ
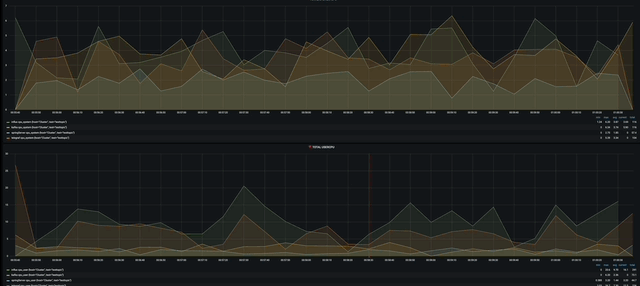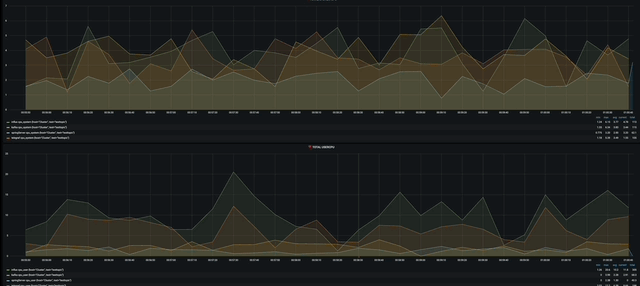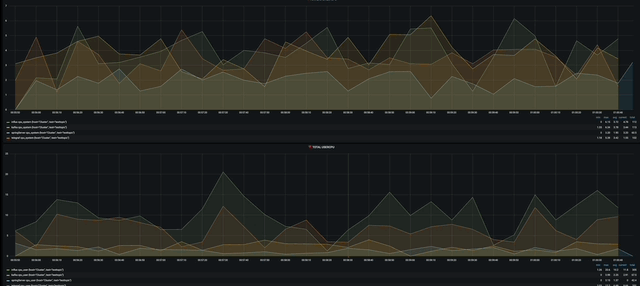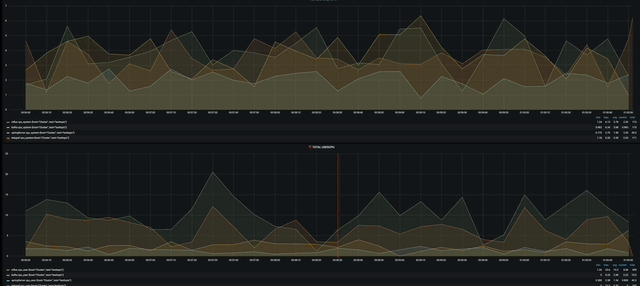 gif다.!!!
물론 경고도 잘 띄워 준다.
gif다.!!!
물론 경고도 잘 띄워 준다.
우선 여기까지 모두 끝났으니 종장으로 가보자!
->다음편7. ToBeContinue…?에서 계속