- Deep RL is a type of Machine Learning where an agent learns how to behave in an environment by performing actions and seeing the results.
- 강화학습은 agent(주체)가 특정 환경에서 action(행동)과 result(결과)에 대해서 어떻게 반응하는지에 대해 배우는 것이다.
What is Reinforcement Learing?
기본적인 아이디어는 AI가 action에 대해서 reaction하고 리워드를 받으면서 환경을 배워나가는 것이다.
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
강화학습은 특정 feedback을 가지고 시행착오를 경험하며 받은 보상(+ || -)을 통해 환경에 반응하면서 배운 AI 모델을 만들고 이를 통해서 control task (결정적인 문제)를 해결하는 framework이다.
The Reinforcement Learning Framework
![[Pasted image 20231009125404.png|]]
RL이 학습을 하는 과정을 위에 도식과 같다.
- Environment에서 Agent에서 state를 St를 주게 된다.
- Agent는 St에 대해 At를 action한다.
- Environment에서는 새로운 state St+1가 생성된다.
- Environment는 또한 At에 따른 결과로 Rt를 Agent에게 feedback한다.
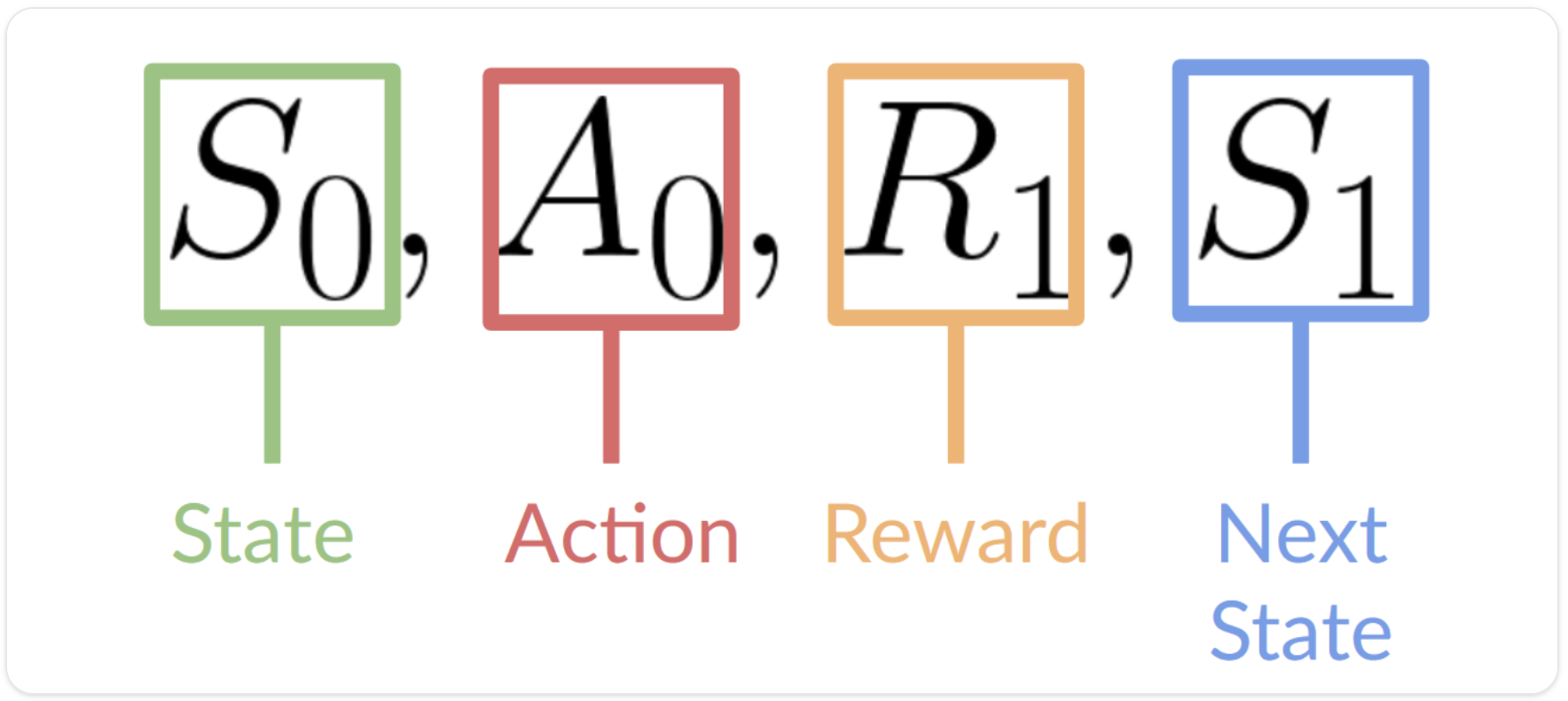
이 4가지 과정이 RL이 학습을 하는 과정인데 크게 state(상태), Action(행동-나는 반응이라고 생각한다), Reward(보상), STATE(새로운 상태)로 구분된다.
강화 학습을 진행하는데 있어서 목표는 maximizing cumulative reward 즉 누적된 보상을 최대화 하는 것이다.
The reward hypothesis: the central idea of Reinforcement Learning
Why is the goal of the agent to maximize the expected return? 왜 보상을 최대로 하는 것을 목표로 하는 거냐?
이유는 기본적으로 reward hypothesis를 깔고 있기 때문이다. reward hypothesis는 모든 학습의 목표는 기대하는 누적 보상을 최대화하는 것을 목표로 하기 때문이다.
Markov Property
RL을 공부하면서 가장 많이 드는 말이 MDP(Markov Decision Property)라는 것이다.
이 말이 의미하는 부분은 우리의 agent(Model)은 다음 행동을 취하기 위해 현재의 상태 St만이 중요하다고 이야기 하는 것이며 이전의 상태(St-1 …)나 반응(At-1 …)이 중요하지 않다는 것이다.
Observation/State Space
Observation/State Space는 Agent(모델)이 현재 상태를 가져오는 현재 환경을 의미한다.


하지만 Observation 과 State은 엄현히 다르다.
State : 현재 상태는 현재 상태를 완벽하게 설명할 수 있는 것을 의미한다.(State외에 숨겨진 정보가 없는 상태) 완벽하게 Observation할 수 있는 상태를 의미한다.
Observation : State의 부분을 설하는 어떤 것을 의미한다. 환경의 일부분을 이야기 할 수 있는 것이다. e.g 슈퍼마리오 같은 경우는 전체 맵이 엄청 넓은데 게임하고 있는 부분만 볼 수 있다. 이때 이상태를 우리는 Observation한다고 할 수 있다.
Action Space
Action Space는 현재 환경에서 Agent가 Action할 수 있는 모든 Set을 의미한다. 이러한 Action은 discrete 혹은 continous space로 부터 정의할 수 있다.
- Discrete Space : Action이 유한한 경우
- e.g. 슈퍼마리오의 경우에는 letf, right, up, down은 무한대로 할 수 있다. 이 경우 이 4가지 경우를 Discrete Space라고 정의 한다.
- Continous Space : Action이 무한한 경우
- e.g. 자율주행 자동차에서 핸들이 움직이는 방향은 각도에 따라 0~360까지 가능하다.
Rewards and the discounting
보상에 대한 누적합은 아래와 같은 수식으로 정의할 수 있다.
… 추후작성