Abrstact
해당 모델은 ImageNet LSVRC-2010에서 우승을 한 모델이다. 이 시점에서는 deep learning에 대한 가능성에 대해서 굉장히 부정적인 시각을 가지고 있었고 모델이 나올 때 까지만 해도 여전히 부정적이 었다. 하지만 모델을 훈련시키는 효과적인 방법을 통해서 발전의 가능성을 보여줬다고 할 수 있었다.
해당 모델은 non-saturating neurons를 사용했고 (ReLU) dropout이라는 기법을 적용해서 overfitting을 줄일 수 있었다.
Introduction
해당 시점에서 CNN은 효과가 어느정도 입증 됨에도 불구하고 많은 리소스의 사용으로 잘 사용되지 못했다. 해당 논문이 기여하는 바는 많은 리소스를 사용하는 CNN을 효과적으로 수행할 수 있는 방안에 대해서 설명 하고 있으며 이를 통해 ILSVRC에서 좋은 결과를 낼 수 있었다는 점을 시사하고 있다.
Dataset
ILSVRC에서 가져올 수 있는 1.2million개의 이미지와 해당 이미지에 있는 1000개의 label을 dataset으로 사용했다.
Architecture
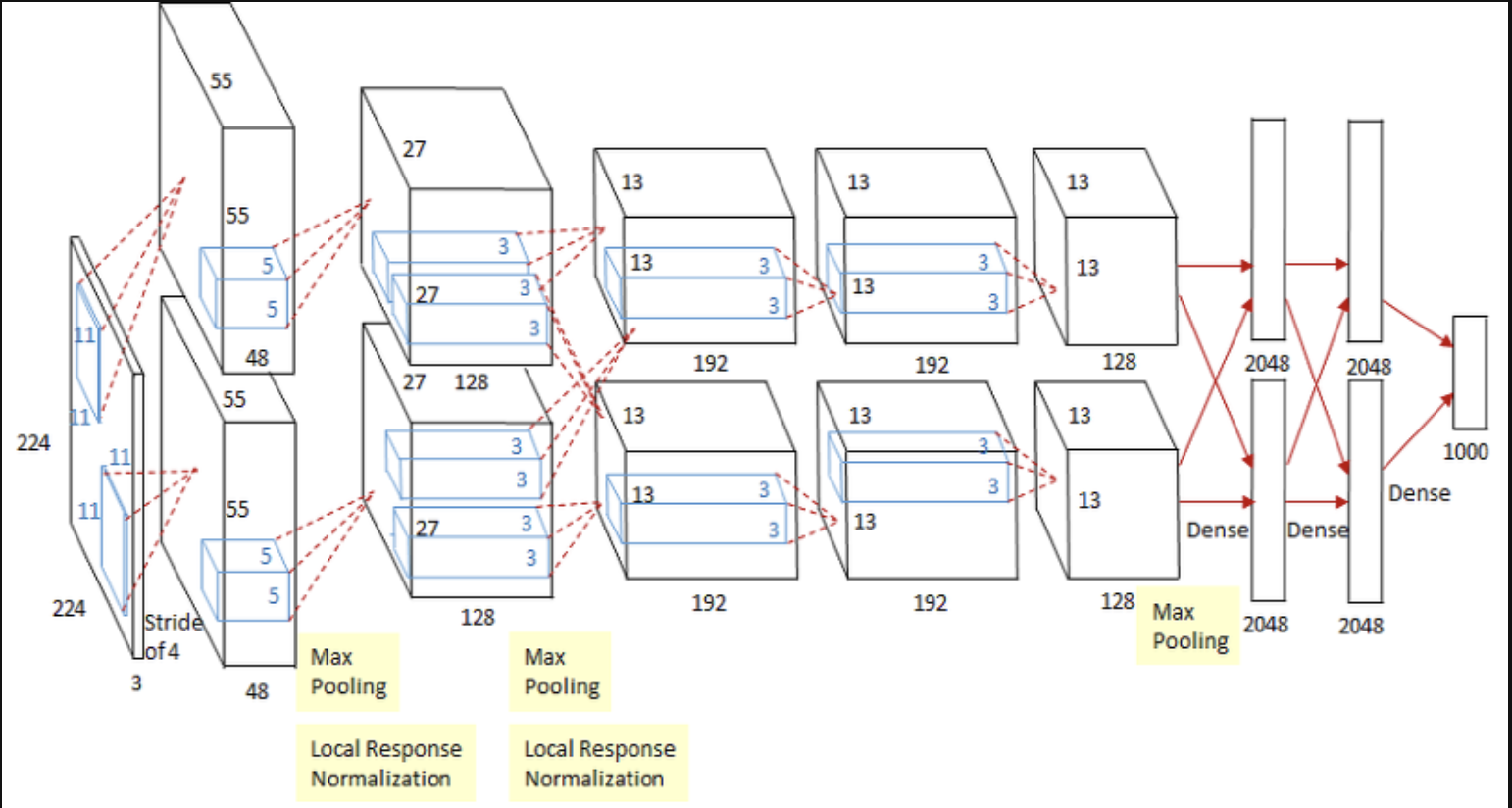
해당 모델의 architecture는 다음과 같이 생겼다.
-
ReLU Nornaliztion
보통에는 tanh나 sigmod함수를 통해서 특징을 판별하곤 한다. 이러한 saturating nonlinearities한 부분의 함수는 non-saturating nonlinearities한 max함수보다는 느리게 된다. 논문에서는 해당 activion fuction에 ReLU라는 함수를 도입하게 된다.
해당 함수는 tanh보다 빠르게 학습시킬 수 있게 된다. 또한 이러한 속도로 인해서 CNN의 많은 ㅅ리소스사용에 따른 느린 속도를 향살 시킬 수 있게 된다.
-
Traning on Multiple GPUs
해당 시점에는 GTX 580이고 3GB정도의 메모리를 가진 모델을 사용한다. 하지만 1.2million의 dataset을 traning시키기에는 굉장히 많은 문제를 가지고 있다고 이야기 한다. 해당 논문에서는 GPU를 병렬처리하게 함으로 써 속도를 향상시킬 수 있었다. 또한 각 레이어는 단계마다 이전 레이어의 feature만을 input으로 받는 부분이 있고 두개의 GPU에서 생성된 feature를 모두 받는 경우로 구조를 설계했다.
-
Local Response Normalization
이부분은 다시 정리 필요
-
Overlapping pooling
풀링 레이어에서는 grid형으로 edge를 기준으로 나누면서 pooling을 진행한다. 하지만 해당 논문에서는 stride를 2로 지정해 나가면서 사이에 겹치는 부분또한 feature를 잃지 않기 위해 같이 진행 한 부분이 있다.
-
Overall Architecture
전체 architecture는 5개의 Conv layer와 3개의 fully connected layer로 이루어 져있다. 또한 마지막에 나오는 parameter는 1000개의 softmax를 통해 1000개의 label 데이터와 매칭 시킬 수 있게 되었다.
또한 2,4,5번 layer는 이전 layer에서만 데이터를 넘겨 받으며 3번 layer에서는 병렬 연산되 GPU의 feature를 모두 받게 된다. input은 224x224x3으로 진행되며 최종적으로는 60million개의 parameter를 가지고 있게 된다.
Reducing Overfitting
위에서 만든 architecture는 60million개의 parameter를 가지고 있게 되며 이는 gradient vanishing문제를 가질 수 있게 한다. 해당 논문에서는 data augmentation과 dropout을 통해 문제를 해결 할 수 있게 하였다.