고정길이 레코드
이전 글에서 설명했던 것 처럼 고정길이 레코드는 블록 내부에서 일정한 크기를 가지는 레코드를 순차적으로 저장하게 된다. 여기서 2가지 문제점이 생긴다.
- block의 마지막 부분에서 record가 잘려서 저장되는 경우
- 삭제시 빈공간에 대해서 저장 공간 누수가 될 수 있다는 점
첫번째 문제점은 블록의 나머지 공간을 버리고 다른 블록을 사용하면 되고 두번째는 블록내부에 header를 하나 놓고 이를 이후에 삭제된 부분을 pointing하면서 삭제 후 삽입을 진행하면된다.
하지만 이 고정 길이 레코드의 한계점이 어느정도 존재한다.
고정길이 레코드의 한계점
우선 데이터의 종류에 따른 문제가 있다.
- varchar와 같은 가변길이 문자열은 레코드의 길이를 특정할 수 없다. 이러한 이유로 고정길이 레코드에 원하는 대로 저장 할 수 없게 된다.
- 어떤 레코드에는 배열과 다양한 값을 가질 수 있는 enum과 같은 것들이 있기 때문이다.
결국 변화하는 레코드에 대응 하기 위해 다른 레코드 형식은 가변길이 레코드 기술이 나오게 된다.
가변길이 레코드
가변길이 레코드는 크게 2개의 부분으로 구성된다.
- 고정길이를 갖는 데이터 부분
- 가변길이를 갖는 데이터 부분
이때 가변 길이는 레코드의 처음 부분에 [오프셋(offset), 길이(length)]를 통해서 데이터를 표현하게 된다. 이러한 형식을 레코드의 앞부분 고정 길이 부분 이후에 이 속성값을 연속적으로 저장한다.
이렇게되면 아래와 같은 구조를 가질 수 있다
레코드 스키마
ID(varchar), name(varchar), dept_name(varchar), salary(Int)
레코드 블록
|21,5|26,10|36,10|65000|0000|10101|Srinivasan|Comp.Sci|
위의 구조를 설명하면 아래와 같다.
- 첫번째 레코드는 21번째 bit 부터 5개의 길이를 가지는 ID 필드
- 두번째 레코드는 26번째 bit 부터 10개의 길이를 가지는 name 필드
- 세번째 레코드는 36번째 bit 부터 10개의 길이를 가지는 dept_name 필드
- 마지막으로 정수형 salary
여기서 65000값뒤에 0000의 null bitmap이라고 부른다. 만약 name과 salary가 null이 허용되고 실제 값이 null로 없다면 null bitmap은 0101이 될 것이다.
슬롯 페이지 구조
이러한 가변길이 레코드를 저장하는 방식은 일반적인 방식과는 좀 다르게 저장되어야한다. 레코드의 길이가 각기 다르기 때문에 기존 고정길이 레코드와는 다르게 저장되어야하고 이는 블록을 header와 record로 정의한다.
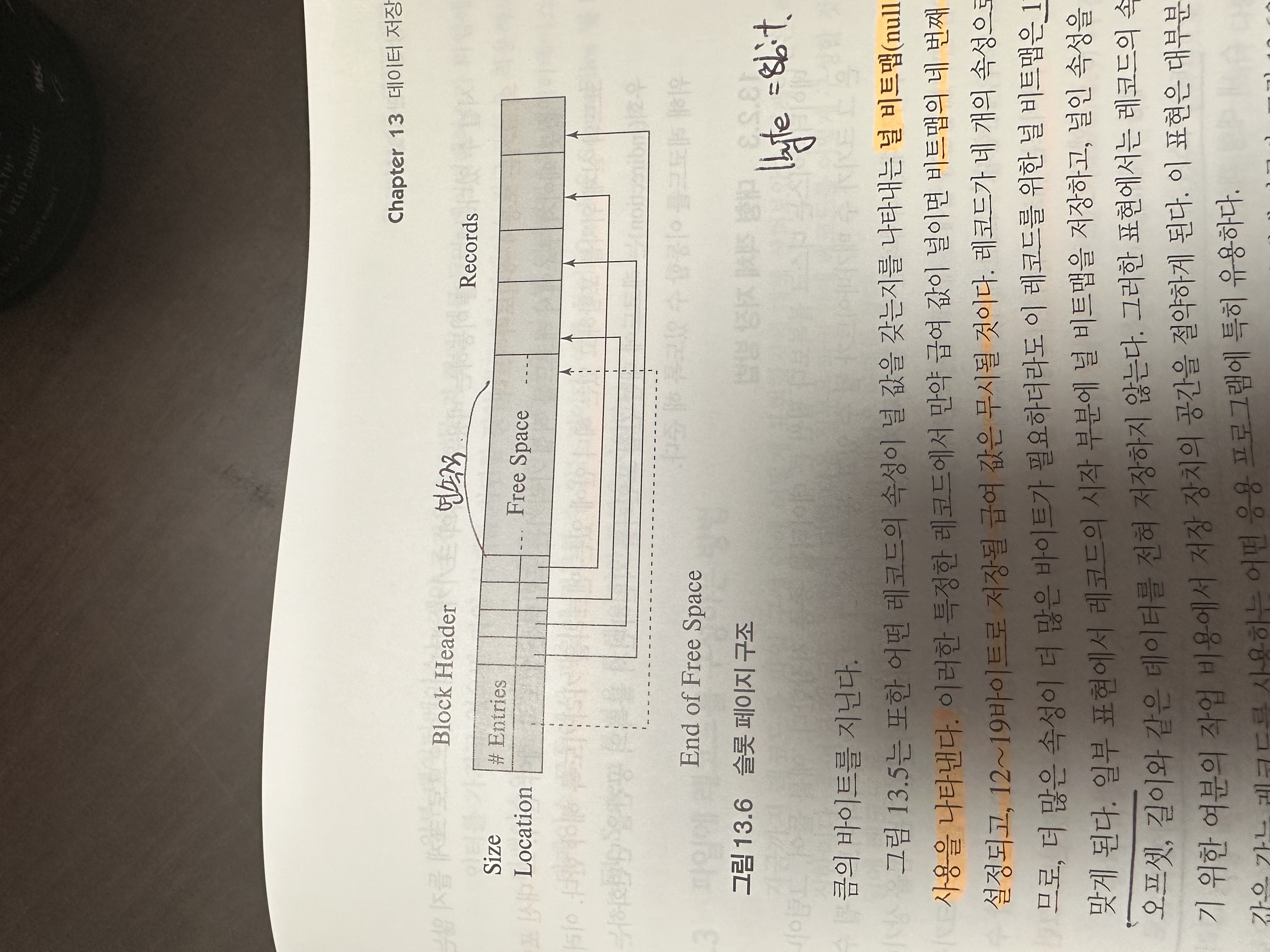 각 헤더에는 다음과 같은 정보가 들어있다.
각 헤더에는 다음과 같은 정보가 들어있다.
- 헤더에 있는 레코드 엔트리수 -> 몇개의 레코드가 있냐?
- 블록에서 빈곳의 끝
- 각 레코드의 위치와 크기를 포함하고 있는 엔트리 배열 (레코드의 위치와 크기)
- 이구조에서 실제 레코드는 블록의 끝에서 부터 인접하게 할당된다. 4KB블록이면 4048bit부터 거꾸로 써진다는 이야기이다.
- #entries는 블록 내부에 비어있는 공간중 가장 마지막 bit를 가리킨다.
- #entries 이후에 붙어있는 pointer들은 각 레코드의 첫bit를 가리키게 된다.
이러한 구조가 되면 가장 마지막 포인터 부터 가장 첫번째 레코드의 사이는 연속적으로 비어있음을 알 수 있다.
이러한 구조에서 레코드를 삭제하면 어떻게 될까?
- 레코드를 삭제하면 해당 pointer를 통해서 실제 레코드를 삭제한다.
- 해당 레코드를 가리키는 pointer를 삭제한 상태로 표시한다. (Entry에서 크기를 -1로 변경 및 포인터 제거)
- 이후 삭제한 레코드 앞쪽에 있는 레코드를 이동해서 빈공간을 제거한다.
- 이후 헤더에있는#entries를 갱신한다.