Abstarct
GoogleNet이랑 동일 competition에 제출했던 논문이고 ILSVRC에서 2등을 차지했던 논문이다. 해당 논문에서 구현한 vgg는 기존에 얕고 넓게 쌓았던 레이어와는 다르게 깊게 쌓는 것을 목표로 했다. 아니 목표로 했다기 보다는 깊게 쌓는 모델에 대해서 검증을 하기 위해 논문이라고 생각한다.
기본 아이디어는 3x3 Conv layer를 이용해서 모델의 깊이를 늘리는 것이 핵심 아이디어다. 또한 ConvNet에서 따온 아이디어를 통해서 깊은 레이어를 쌓으려고 했다.
Introduction
일딴 2등을 한 것에 대한 변명을 좀 한다. 2등을 했지만 GoogleNet보다 좀 더 general하게 모델에 기여 할 수 있다고 이야기한다.
- ConvNet Configurations
이 부분에서는 모델에 여러가지 특성에 대해서 이야기 한다.
- Architecture
첫번째로는 Architecture에 대해서 이야기 한다. 우선적으로 input size는 224x224에 RGB로 한정했다. 여기서 전처리를 했던 부분은 RGB값에 대한 normalization을 이용해서 픽셀에 차이가 많이 나는 것에 대한 정규화를 진행했다. 그리고 3x3 Conv layer와 1x1 Conv layer를 통해서 이전에 ConvNet과 다르게 특징을 좀 더 많이 뽑아낼 수 있겠다.
뒤에 나오겠지만 해당 논문의 모델은 여러가지 모델을 비교하면서 최적의 성능을 찾가는 과정을 그리고 있다.
여기서 stride는 1정도로 해주고 padding 또한 1pixel로 진행하며 5개의 max-pooling layer를 넣어 놓았다.

이 부분이 좀 이해가 안되는데 Max-pooling이 2x2로 stride2만큼 움직이면서 5번있다는 이야기 인듯 한다. (일딴)
마지막에 fully Connected layer는 4096으로 합치고 이를 1000개의 feature로 만들어 준다. activation function은 ReLU로 진행해서 비선형성을 유지해 줬다. 마지막으로 Local Response Normalisation은 메모리만 잡아 먹고 유용하지 않다고 이야기한다.
- Configuration
환경설정이라고 하는 것 같은데 비교군과 대조군 뭐 이런 것들을 설정하는 느낌이 었다.
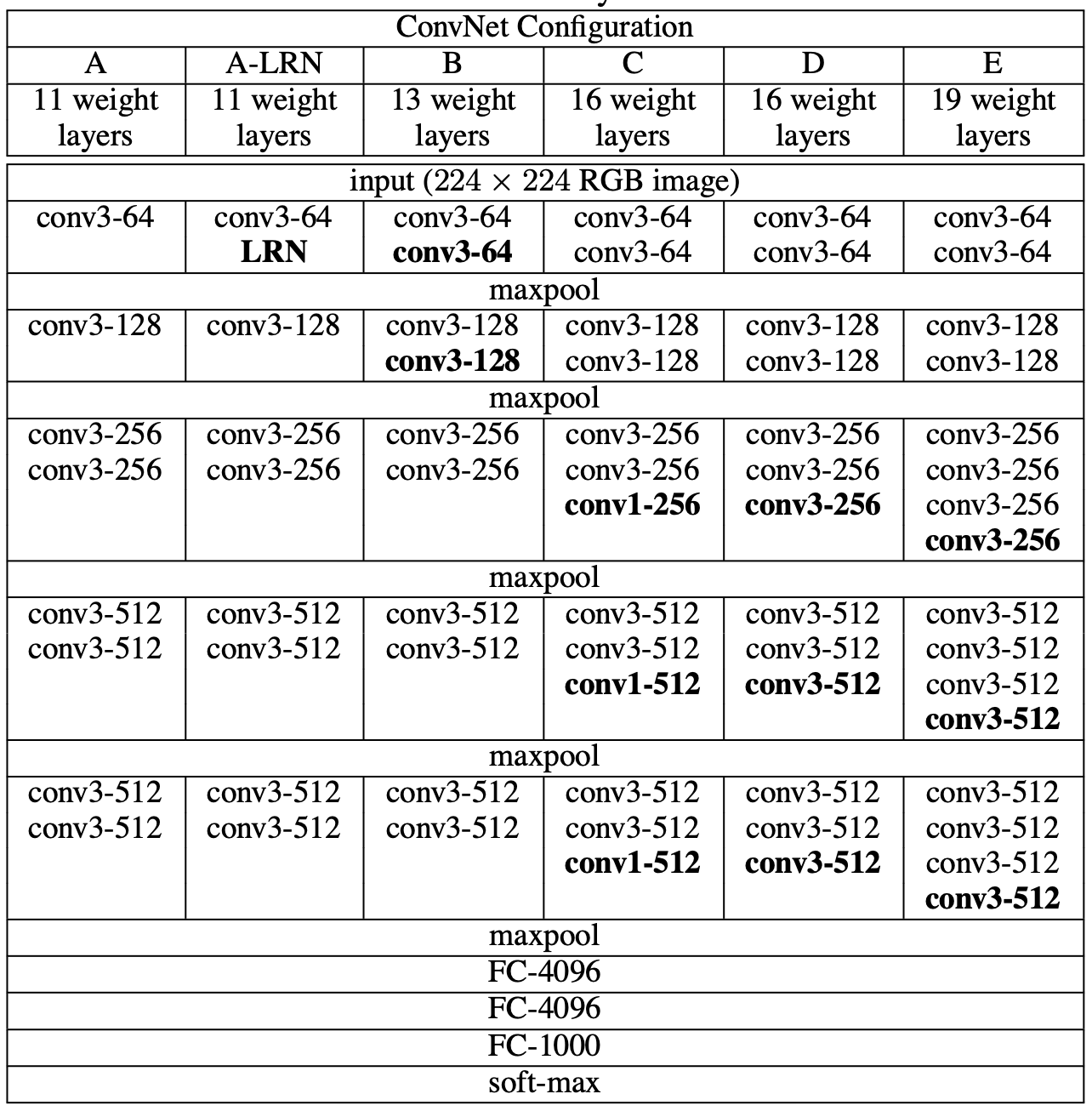 A는 11개의 weight layer
A-LRN는 11개의 weight layer를 사용하지만 초기에 Local Response Normalisation을 적용한 것이다.
B는 13개의 레이어를 적용했는데 초기에 2개의 레이어를 쌓고 이후로는 점점 레이어를 추가해 가면서 모델을 발전시켜 나갔다.
A는 11개의 weight layer
A-LRN는 11개의 weight layer를 사용하지만 초기에 Local Response Normalisation을 적용한 것이다.
B는 13개의 레이어를 적용했는데 초기에 2개의 레이어를 쌓고 이후로는 점점 레이어를 추가해 가면서 모델을 발전시켜 나갔다.
- Discussion 이 부분의 도입부에서는 이전에 넓고 얕게 쌓는 모델들은 통상 7x7 Conv layer를 통해서 feature를 뽑아냈기 때문에 깊게 쌓지 못한다고 이야기 한다. 해서 vgg모델은 3x3모델을 통해서 좀 더 많은 채널을 뽑아내면서 깊게 쌓을 수 있다고 이야기 하고있다.
- Training
 이부분은 내가 이해하는 바로 vgg는 multinomial logstic regression을 사용했다고 하는데 이부분이 잘 이해가 가지 않는다.
이부분은 내가 이해하는 바로 vgg는 multinomial logstic regression을 사용했다고 하는데 이부분이 잘 이해가 가지 않는다.
뒷부분은 normalization에 대한 이야기 인데 초기 4개 레이어의 가중치값과 마지막 3개 레이어의 가중치 값을 initalisationr값으로 사용한 것 같고 각 값은 0~0.01까지의 가중치를 가진다.
또한 초기 224x224의 이미지는 crop 되거나 수평으로 회전되거나 RGB 색이 변경되는 등의 Augmentation을 통해서 다양한 input을 생성하려고 했다.
-
tranning image size 이 부분은 training Augmentation에 관한 이야기 인데 input이 224가 아닌경우에는 crop을 통해서 진행하거나 256 과 512사이의 값으로 변환해서 사용한다고 했다.
-
testing
 테스팅 부분은 train, test부분은 inpu과 aug값이 일치하지 않게 진행을 했다. → 이부분도 정확하게 읽히지가 않습니다.
테스팅 부분은 train, test부분은 inpu과 aug값이 일치하지 않게 진행을 했다. → 이부분도 정확하게 읽히지가 않습니다. -
implementation 실행하는 방법에는 C++로 짰다고 했고 GPU를 사용해서 진행했다고 한다.
-
Classification Experiments dataset은 ILSVR에서 제공하는 1.3M의 train, validation 50K, 100K의 held-out class label을 사용했다고 한다.
-
Conclusion
sigle Scale과 multi Scale은 이미지를 줄이는 방법에 대한 이야기이다.
Single Scale
해당 scaling 방법은 최초 input에 대해서 작은 변에 대해서 256으로 scale down시켜주고 이렇게 학습한 가중치를 384크기로 scaling한 값에 사용한다. 이러한 방법으로 학습시킨 것이 Single Scale 이다. 이후에 single scaling과 마찬가지로 224 size로 crop 후 사용한다.
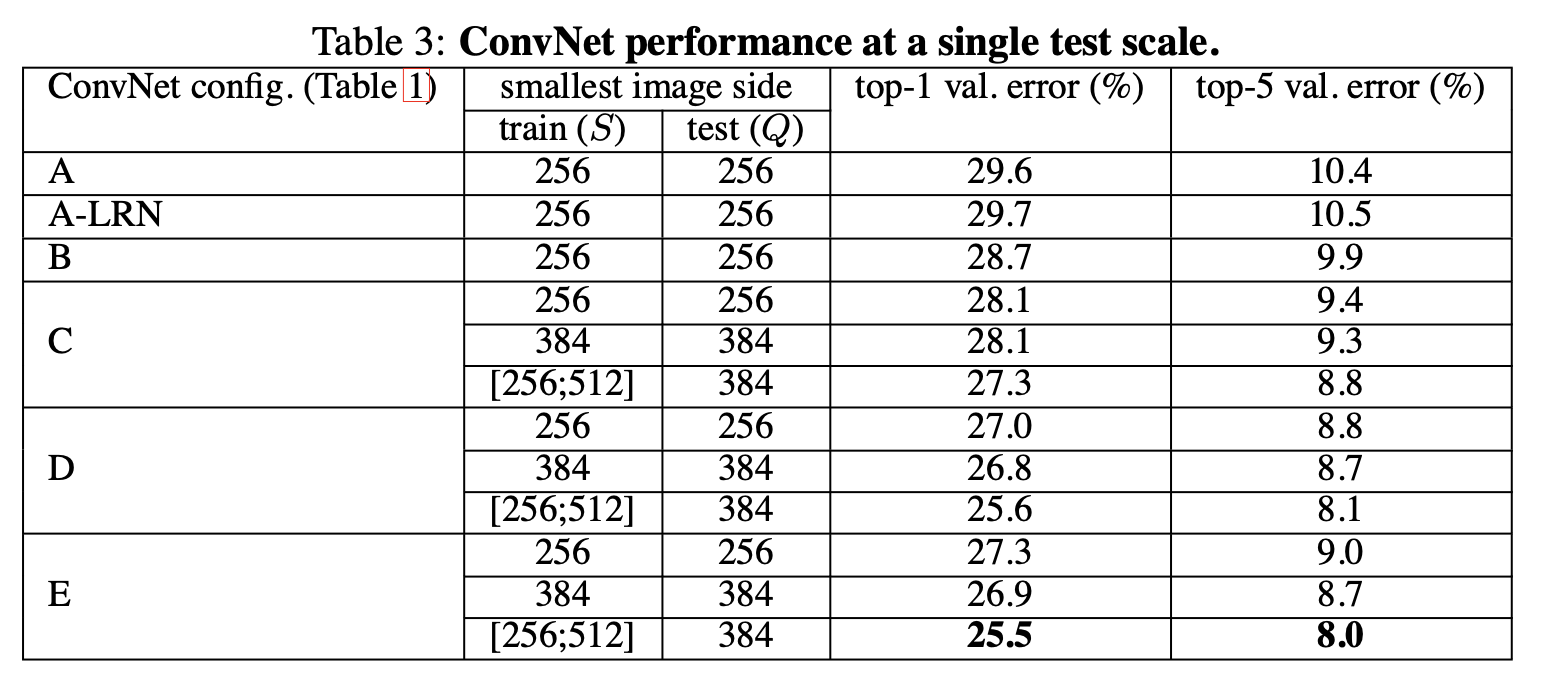
single test scale에서의 결과인데 확인해 보면 E에서 가장 낮은 error율을 보여주는 것을 알 수 있다.
Multi Scale
multi Scale은 최초에 input을 Smin :=256 Smax := 512사이로 scaling을 진행한다. 이후에 single scaling과 마찬가지로 224 size로 crop 후 사용한다.
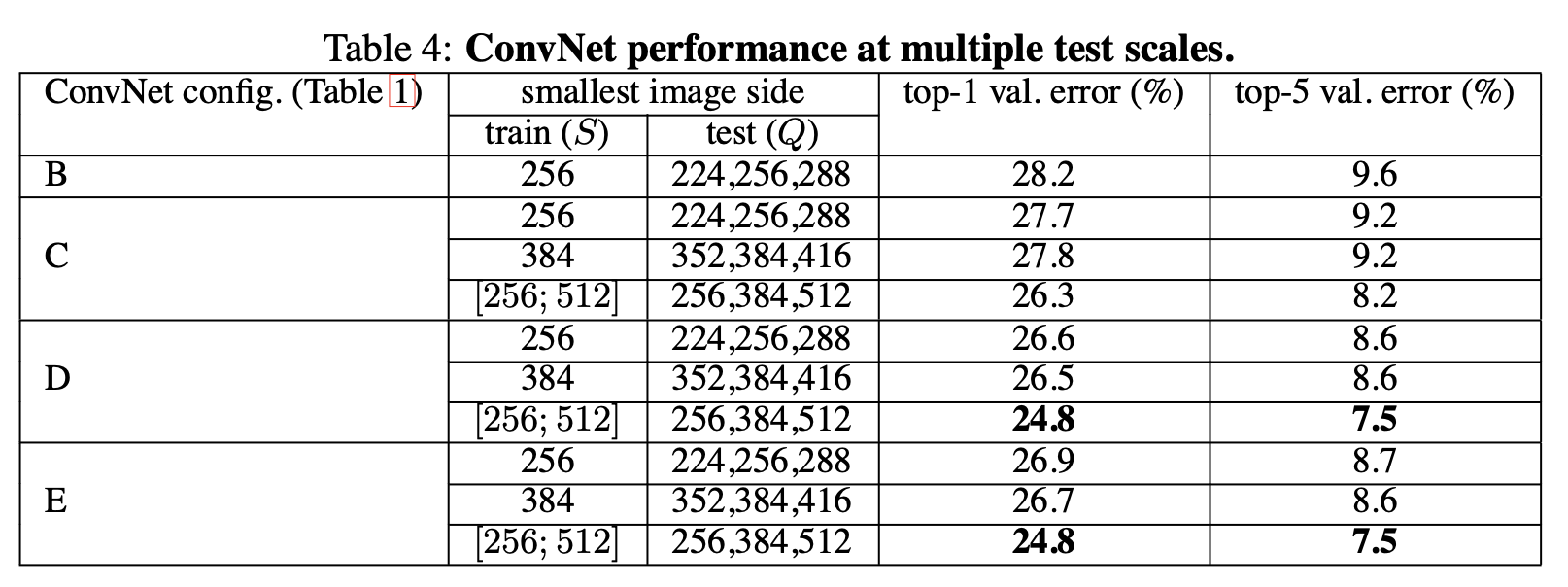
multi scale에서는 D와 E가 같은 성능을 보여주고 있는데 주목할 만한 점은 E가 D보다 깊은 레이어를 쌓았지만 error성능은 비슷한 것으로 나왔다. 이러한 결과가 후에 ResNet에 대한 어떤 시그널일지도 모른다. 여튼 결과적으로 파라미터도 D가 더 낮은 상황에서 스코어가 같게 된다면 굳이 더 깊이 쌓아서 시간을 늘릴 필요가 없기 떄문에 vgg는 vgg19보다 vgg16이 더 많이 각광 받았던 것 같다.
Q : 과연 Single Scale과 multi Scale의 차이점이 무엇인가?
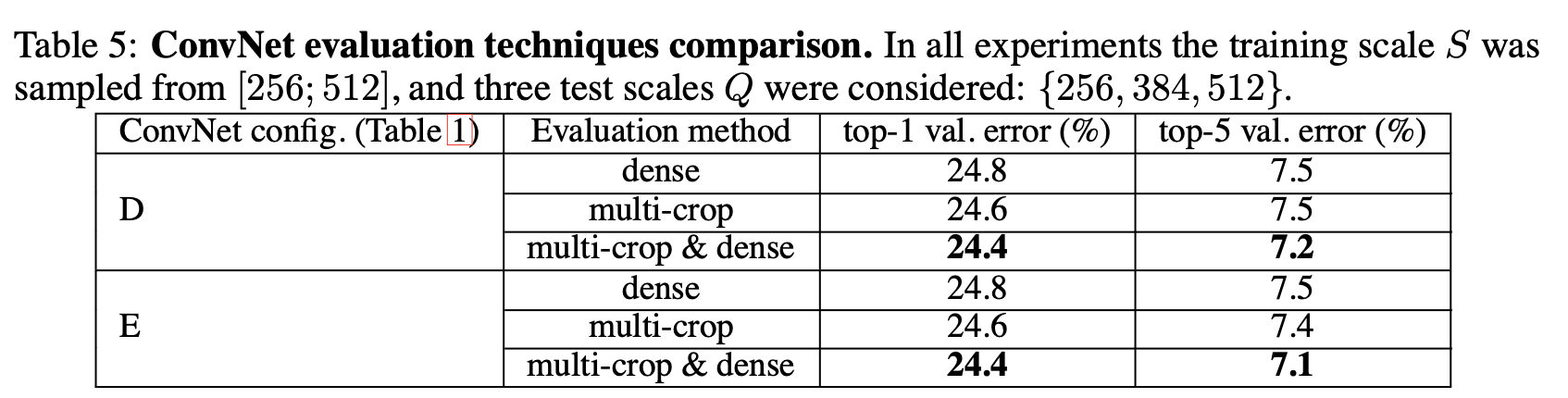 Multi Crop and Dense
다양한 방식으로 crop를 하고 깊게 쌓았을 때를 비교해 보면 E의 성능이 아주 미약하게 낮지만 큰차이는 보여주지 않는 것으로 나타났다.
Multi Crop and Dense
다양한 방식으로 crop를 하고 깊게 쌓았을 때를 비교해 보면 E의 성능이 아주 미약하게 낮지만 큰차이는 보여주지 않는 것으로 나타났다.이 뒤는 여러개의 논문과 비교했다는 이야기고 성능이 좋았다는 이야기를 하는 것이다.