1. Overview & IDEA - HW monitoring 2. Problem & PoC 3. DATA Design 4. Publisher 5. Database & logger 6. Visualization 7. ToBeContinue…?
Publishing
이전까지는 열심히 시스템 리소스를 잡아왔고 이제 KAFKA로 데이터를 전송하는일이 남았다. 코드는 생각보다 간단한데 아래와 같다.
final String TOPIC_NAME = "fooo";
String bootstrapServer = args[0] + ":9092";
System.out.println("bootstrap server : " + bootstrapServer);
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServer);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, HardWareUsageDAO> producer = new KafkaProducer<>(properties);
//### 하드웨어 리소스를 잡아오는 코드 ###
hardWareUsageDAO.setCPU(cpuDetail).setDISK(diskDetail).setMEM(memDetail).setTopRateProcess((ArrayList<TopProcessDetail>) topRateProcess);
// sending kafka
ProducerRecord<String, HardWareUsageDAO> record = new ProducerRecord<String, HardWareUsageDAO>(TOPIC_NAME, hardWareUsageDAO);
try {
producer.send(record);
System.out.println(hardWareUsageDAO);
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}Serializer
보면 그렇게 어려운 상황은 아니다. 다만 주석에 적혀있듯이 Jsonserializer가 난관이었다. 많은 예제들에서 단순히 text를 보내면서 “아 저렇게 하면 되는 구나”했고 이번 프로젝트에서는 뭔가 다른걸 해보려다가 많은 시간을 들였던 부분이었다. 자세한건 Java Serializable에서 확인하자.
잘 못된 코드
JsonSerializer.ADD_TYPE_INFO_HEADERS, {Object class}.class.getName()
잘 못된 코드위코드를 통해서 JsonSerializer에서 해당 Object를 추론 할 수 있게 해줘야한다.
잠깐의 프로젝트 코딩의 경험으로 Serializer에 대해서 생각해보면 각 객체 혹은 text(string)을 byte로 바꾼 뒤 필요한 작업을 하고 다시 역으로 객체 혹은 text(string)으로 바꿔서 데이터의 교환을 원활하게 해주는 역할을한다.
Object -> 직렬화 -> byte
"hello" -> b"hello"
byte -> 역직렬화 -> Object
b"hello" -> hello
위와 같은 느낌인건데, 문자열은 생각보다 그냥 그렇구나 하지만 객체는 조금 다르다.
구현한 데이터 객체를 하나 보게 되면 아래와 같다. 이부분에서 문제가 있는데 TopProcessDetail은 HardWareUsageDAO(DTO가 더 맞는 작명이었긴 하겠네)에 속한 객체로 모델링 되어있다. 근데? 원래 HardWardUsageDAO는 아래와 같다.
public class HardWareUsageDAO {
/*
TotalCpuDetail CPU HardWare Total Usage
This is divided into [User, System]
TotalMemDetail MEM HardWare Total Usage
This is divided into [Used, Unused] TotalDiskDetail
Disk is HardWare Total Usage This is divided into [Read, Write] TopProcessDetail This is COMMAND TOP result where ranked top 5 This is consist of [PID, COMMAND, CPUusag˜e, Time, Mem, State]
***** Important ***** FOR USE JSON DAO MUST TAKE DEFAULT CONSTRUCTOR ***** Important ***** */
private String EC2Number;
private TotalCpuDetail CPU;
private TotalMemDetail MEM;
private TotalDiskDetail DISK;
private List<TopProcessDetail> TopRateProcess;
public HardWareUsageDAO() {
this.TopRateProcess = new ArrayList<TopProcessDetail>();
}
public HardWareUsageDAO(String EC2Number, TotalCpuDetail CPU, TotalMemDetail MEM, TotalDiskDetail DISK, List<TopProcessDetail> topRateProcess) {
this.EC2Number = EC2Number;
this.CPU = CPU;
this.MEM = MEM;
this.DISK = DISK;
TopRateProcess = topRateProcess;
}두개의 다른점은 Serializable을 implements하느냐 마느냐의 차이였다. 요부분은 조금 중요한데 이번에 refactoring하면서 알게된 것이다.
- 부모 객체 : Serializable, 자식 객체 : x -> 직렬화 가능
- 부모 객체 : Serializable, 자식 객체 : Serializable -> 직렬화 가능
- 부모 객체 : x, 자식 객체 : Serializable -> 직렬화 불가능
결과적으로 부모객체에 Serializable이 없는데 하라고 했으니… 참… 부끄러운 코드였다…
public class TopProcessDetail implements Serializable{
/*
***** Important ***** FOR USE JSON DAO MUST TAKE DEFAULT CONSTRUCTOR ***** Important ***** */ private int PID;
private String COMMAND;
private float CPUusage;
private String Time;
private float Mem;
private String State;
@Override
public String toString() {
return "TopProcessDetail{" +
"PID='" + PID + '\'' +
", COMMAND='" + COMMAND + '\'' +
", CPUusage='" + CPUusage + '\'' +
", Time='" + Time + '\'' +
", Mem='" + Mem + '\'' +
", State='" + State + '\'' +
'}';
}
public TopProcessDetail(int PID, String COMMAND, float CPUusage, String time, float mem, String state) {
this.PID = PID;
this.COMMAND = COMMAND;
this.CPUusage = CPUusage;
this.Time = time;
this.Mem = mem;
this.State = state;
}
/*getter setter 생략*/객체는 기본적으로 직렬화 될 때 직렬화 도구마다 다를 수 있지만 JsonSerializer를 사용할 때 Json구조로 문자열화가 된다.
// TopProcessDetail은
{
COMMAND : OOO,
CPUusage : OOO,
Time : OOO,
Mem : OOO,
State : OOO
}
// 이런식으로 넘어가게 될텐데 이를 직렬화 하게 되면
b"{
COMMAND : OOO,
CPUusage : OOO,
Time : OOO,
Mem : OOO,
State : OOO
}"
//요렇게 되게 되는 것이고 역직렬화를 해도 마찬가지이다.중요한 부분은 아래 코드가 설정에 들어간다는 것인데 이 이야기는 코드를 조금더 까보면 알 수 있을 것 같다. 실제 JsonSerializer를 까보면 위에 ADD_TYPE_INFO_HEADERS값이 string으로 특정 Object인 것을 확인 할 수 있는데 KAFKA메시지에 TYPE을 추가하는 부분인거 같은데 잠시대기
까보면 알 수 있는 부분이 아니다 애초에 직렬화 할 수 없는 객체를 만들어 놓고 이상한 곳에서 통을 파고있어서 문제 였다. 아래 코드는 의미가 없다. Header에 관한 설정인데 전혀의미가 없고 해결은 객체 코드를 변경해서 했다.
무지에서 오는 삽질
properties.put(JsonSerializer.ADD_TYPE_INFO_HEADERS, {Objectclass}.class.getName())
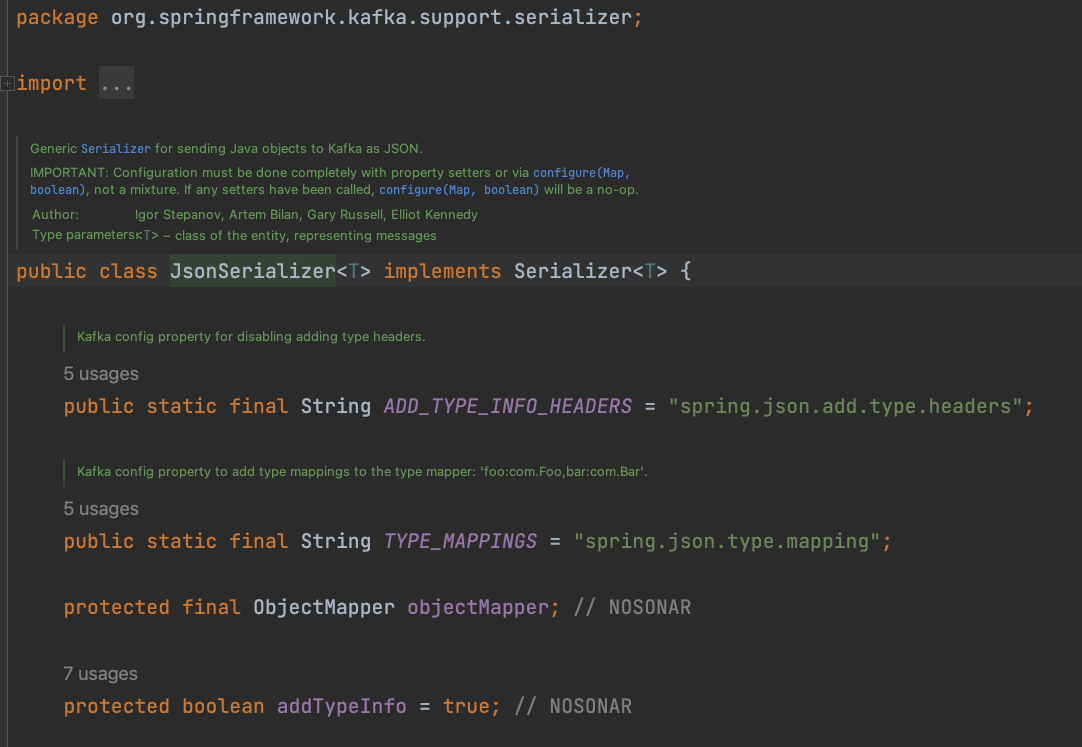
정상 해결 방안
결국 객체를 직렬화 하는 건 Serializable을 implements하는 건데 요부분은 따로 다뤄야겠다…했지만 위에 문제를 설명해 놓음
public class HardWareUsageDAO implements Serializable Publish
이렇게 해서 직렬화를 마치고 KAFKA로 보내주면 아래와 같은 상황을 볼 수 있다.
 보면 뭔가 싶지만 왼쪽 - 카프카, 중간 - producer, 오른쪽 - kafka console consumer이다.
요런 상황까지 왔다면 이제 눈으로 봐야하지 않겠는가!!!!
보면 뭔가 싶지만 왼쪽 - 카프카, 중간 - producer, 오른쪽 - kafka console consumer이다.
요런 상황까지 왔다면 이제 눈으로 봐야하지 않겠는가!!!!

다만 문제는 이전에 종연이가 짠 ELK코드가 없다… 프로젝트를 제안한 사람으로써 문제가 많은 상황이지만 여기서 조질수는 없다…

최근에 MQTT 프로젝트를 공부하면서 influxdb와 그라파나의 유용성을 한번 경험해 봤다. 한번 해보자!!!
->다음편5. Database & logger에서 계속