울면서 한 프로젝트입니다...
1. Overview & IDEA - PPT Searching 2. Extracting with PPT 3. TF-IDF with PPT 4. Threading with PPT 5. Operating with PPT
Trouble
당시에 ppt를 예시로 본게 많아봤자 50장정도 였다. 이는 충분히 짧은 시간안에 추출이 가능했고, 추후에 설명하겠지만 다른 문서군은 따로 뽑아서 matrix를 가지고 있다가 업데이트 하는 형식으로 진행하려 했기 때문에 문서를 추가해도 문제가 되지 않았다.
하지만? 역시 문제는 생긴다… 3시간을 돌려도 한폴더를 끝내지 못하는 상황이 나왔다…

당시 ppt가 300장 넘어가는 파일들이 존재했다…
열어보니 여는데 한 10분 걸리고 파일들도 무거워서 잘 넘어가지도 않는 ppt가 여기저기 폭탄처럼 박혀있었다. 하루 종일돌리고 퇴근 했는데도 잘 안되길래 하나하나 까보니 결국 지뢰를 찾아냈는데 슬라이드만 300장이 넘더라…
일딴 한숨 한 번 쉬고 생각을 해봤다. 하긴 해야되는데 어떻게 하지…?라는 생각이 들고 학교에서 운영체제 돈내고 배우 때 생각이 났다.! 쑤레딩 feat. 공룡책

실전 Threading
학교 과제로 네트워크나 운영체제에서 thread를 사용한적이 있다. thread를 이용해서 convolution filtering의 성능을 높여 보기도 하고 네트워크에서 TCP 연결하는 서버를 만들때 사용해 봤던 기억을 더듬어 본다
자 다시 문제로 돌아오면
- PPT 슬라이드가 너무 많아서 추출을 하는데 너무 많은 시간이 걸린다.
- 시간을 줄여야 문서군의 사이즈를 줄이지 않으면서 가중치를 뽑아낼 수 있다.
라는 부분이고 이를 위해 threading을 계획한다.
문제 부분은 PPT에서 슬라이드를 추출해서 ppt_name : keyword로 추출하는 부분이 문제이기 때문에 2. Extracting with PPT 부분의 코드에서 Threading을 진행해야한다.
원래 코드는 아래와 같다.
def extract_pptx_low_text_str(ppt_name):
low_text_list = ""
input = Presentation(ppt_name)
for slide in input.slides:
for shape in slide.shapes:
if shape.shape_type == MSO_SHAPE_TYPE.TABLE:
low_text_list += extract_pptx_cell_text(shape)
if not shape.has_text_frame:
continue
for paragraph in shape.text_frame.paragraphs:
low_text_list += paragraph.text + " "
return low_text_list.rstrip()몇백장에 ppt를 뽑아내기 위해서는 start 와 end pointer를 두고 이 두 pointer사이의 슬라이드를 추출하고 마지막에 join해서 문서를 빠르게 훝는 전략이었다.
def extract_ppt_low_text_str_threading(ppt_name, start, end):
low_text_list = ""
print(f"Current thread ID: {threading.get_ident()}")
scope_slides = list(Presentation(ppt_name).slides)[start:end+1]
for slide in scope_slides:
for shape in slide.shapes:
if shape.shape_type == MSO_SHAPE_TYPE.TABLE:
low_text_list += extract_pptx_cell_text(shape)
if not shape.has_text_frame:
continue
for paragraph in shape.text_frame.paragraphs:
# print(paragraph.text)
low_text_list += paragraph.text + " "
return low_text_list.rstrip()코드는 크게 달라진게 없다.
여기와 함께 folder2data 함수도 변경되어야 했다. Thread를 생성하고 join하는 부분이 당연히 있어야 하며 slide가 몇장이 넘어갈 때 Thread수에 따라서 작업을 할당하는 코드가 들어갔다.
원래 코드는 아래와 같다.
def folder2data(any_folder_path):
return_dic = {}
f_list = os.listdir(any_folder_path)
pattern = r"\.pptx$"
print(
" now extracting in {} folder wiht length {} loading...".format(
any_folder_path, len(f_list)
)
)
start = time.time()
for file_path in f_list:
absoulte_folder_path = os.path.join(any_folder_path, file_path)
if os.path.isdir(os.path.join(any_folder_path, file_path)):
child_path = os.path.join(any_folder_path, file_path)
return_dic.update(folder2data(child_path))
elif (
errorFileDetection(absoulte_folder_path)
and re.search(pattern, file_path)
and file_path.find("~$") == -1
and os.stat(os.path.join(any_folder_path, file_path)).st_size > 0
):
parent_path = os.path.join(any_folder_path, file_path)
return_dic.update(file2data(parent_path))
print(" end extracting in {} folder...".format(any_folder_path))
end = time.time()
print(" extracting folder time {} sec".format(end - start))
return return_dic이를 Threading으로 바꾸게 되면 아래와 같은 코드가 된다. 따로 추가된 부분은 주석으로 설명한다.
def folder2data_threading(any_folder_path):
return_dic = {}
f_list = os.listdir(any_folder_path)
pattern = r"\.pptx$"
print(
" now extracting in {} folder wiht length {} loading...".format(
any_folder_path, len(f_list)
)
)
start = time.time()
for file_path in f_list:
absoulte_folder_path = os.path.join(any_folder_path, file_path)
# 최상단에 있는 조건문은 file중에 ~$가 붙은 파일은 현재 어떤 이유로열려있는 파일이다.
# 해당파일은 읽을 수 없기 때문에 예외처리를 해줘서 넘긴다.
if (
errorFileDetection(absoulte_folder_path)
and re.search(pattern, file_path)
and file_path.find("~$") == -1
and os.stat(os.path.join(any_folder_path, file_path)).st_size > 0
):
print(" this is in Threading Part")
parent_path = os.path.join(any_folder_path, file_path)
# Thread Programming
print(" out Thread")
# 이부분부터 Thread가 들어가는데 기준을 100장으로 정했다.
# cpu count를 세서 최대 값을 할당했다.
if len(Presentation(parent_path).slides) > 100:
print(" in Thread")
cpu_count = multiprocessing.cpu_count()
print(cpu_count)
thread_epoch = len(Presentation(parent_path).slides) // cpu_count
print(thread_epoch)
thread_result = []
threads = []
thread_result_str = ""
for epoch in range(cpu_count):
t = threading.Thread(
target=lambda: thread_result.append(
extract_ppt_low_text_str_threading(
parent_path,
epoch * thread_epoch,
(epoch + 1) * thread_epoch,
)
)
)
threads.append(t)
t.start()
for runned_thread in threads:
runned_thread.join()
for result in thread_result:
thread_result_str += result + " "
temp_dic = {}
temp_dic[parent_path] = thread_result_str
return_dic.update(temp_dic)
else:
parent_path = os.path.join(any_folder_path, file_path)
return_dic.update(file2data(parent_path))
elif os.path.isdir(os.path.join(any_folder_path, file_path)):
child_path = os.path.join(any_folder_path, file_path)
return_dic.update(folder2data_threading(child_path))
print(" end extracting in {} folder...".format(any_folder_path))
end = time.time()
print(" extracting folder time {} sec".format(end - start))
return return_dicThread수를 수정하면서 테스트해봤을 때 는 아래와 같다.
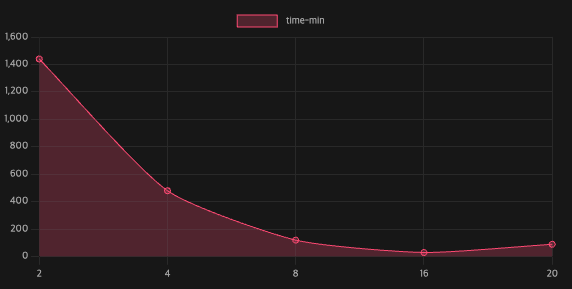
분으로 환산한 값들을 적었고 당시에 걸렸던 시간을 어림잡아 다시 쓴 값이다. Thread 1개 :퇴근하고 출근해도 안됨 Thread 2개 :출근해서 돌리면 퇴근할 때 끝남 Thread 4개 : 한 6시간 정도로 정리가능 Thread 8개 : 한 2시간 정도로 정리가능 Thread 16개 : 30분 이내로 정리가능 그이상은 Thread할당하는 시간 때문에 늘어나는 걸 보여줬다.
해당 문서군은 약 100GB정도 였던 것으로 기억한다. 정확하게 문서 만에 크기를 재보지는 않았지만 꽤 많지 않았나 하는 생각을 한다.
결과적으로는 빠른 시간안에 끝낼 수 있도록 최적화 작업을 진행하고 이를 통해 추천을 할 수 있는 matrix를 뽑을 수 있게 되었다.
->다음편5. Operating with PPT에서 계속
type: line
labels: [2,4,8,16,20]
series:
- title: time-min
data: [1440, 480 ,120, 30,90]
tension: 0.2
width: 80%
labelColors: false
fill: true
beginAtZero: true
bestFit: false
bestFitTitle: undefined
bestFitNumber: 0