Abstract
해당 논문은 inception이란 컨셉을 통해서 convolution layer 더 깊고 넓게 쌓을 수 있다고 주장하고 있고 이를 통해 computing resource를 줄일 수 있는 방법을 제안한다고 이야기한다.
Intro
googleNet은 ILSVRC 2014(?)년도에 1등을 한 모델인데 이는 전전 년도의 1등인 Kzizhevsky et. al보다 12개의 parameter를 더 많이 사용한 것으로 나타났다고 한다.
또한 해당 시기의 CNN은 연산을 많이 하는 특징이 있었는데 이러한 특징이 embeded computing을 위한 효율적인 방안으로 진화해야하는 맹점을 가지고 있었다. 때문에 해당 년도에는 성능을 높이기 위해서 layer더 깊게 쌓기도 했지만 최적화를 위한 많은 방법을 찾고 있었다.
해당 논문에서 말하는 deep이라는 말에는 2가지의미가 내포되어 있다. 이는 단순하게 layer를 깊게 쌓는 것과 inception module을 통해 더 효율적으로 쌓을 수 있다는 의미를 포함한다.
Related Work
요약하자면 해당 년도에는 CNN이 많이 발전하고 있는 시기였고 최적화 과정을 위해 다양한 알고리즘을 개발하고 정확성의 향상을 위해 더 깊은 layer를 만들고 있었다.
문제는 2가지가 존재하는데 첫번째는 모델을 깊게 쌓으면 Overfitting의 문제가 존재하게 된다. 학습 데이터 셋이 방대하지 않는 이상 모델이 깊어지게 되면 Overfitting문제가 생겨서 정확성이 떨어지는 모델이 될 수 있다.
두번쨰 문제는 Network size가 깊어질 수록 연산량이 증가하다는 점이다. n x n Conv를 2개 쌓는다고 하자. 그럼 HxWxC가 n x n을 거쳐서 HxWxC1으로 나오게 되고 이를 다시 Conv에 넣으면 HxWxC2가 나온다. 이때 전체 연산량은 C1 x C2 만큼 됨으로 layer가 1개 늘어나면 연산량은 제곱으로 늘어나게 되는 것이다.
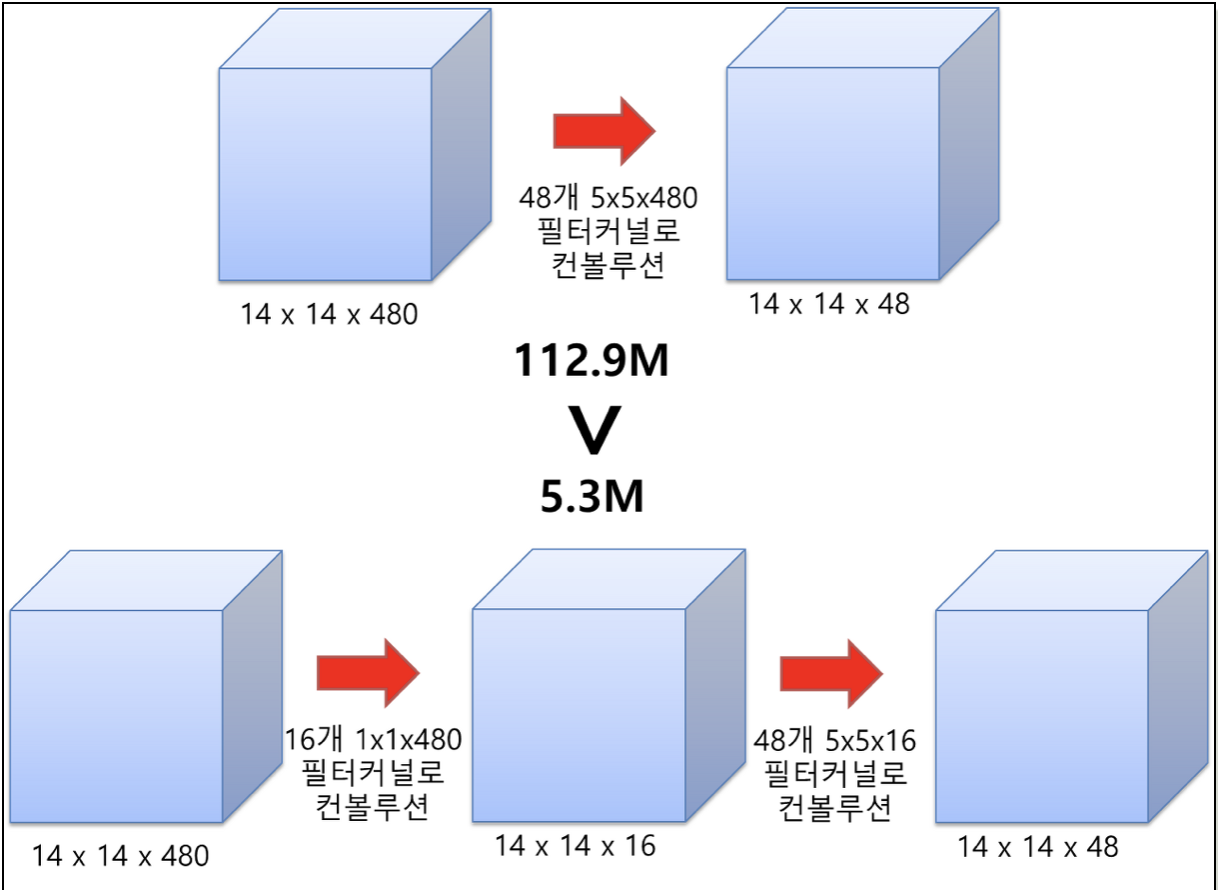
해서 저자들이 생각한 방법은 네트워크를 깊게 쌓는 대신 효율적으로 쌓자 뭐 이런겁니다….
논문에 보게 되면 spars라는 말이 나오는데 이는 덜연결된 희소한 이런 뜻으로 받아들였습니다. 해서 Network를 만들어 다음 layer로 정보를 전달할 때 연관된 정보만을 연결해서 연산을 진행하면 좀 적게 연산을 할 수 있지 않을까? 라는 아이디어 였지만…. 잘 안된 것 같다고 논문에도 그렇고 여러 블로그에도 나와있는 것 같습니다.
Architecture Detail
- Inception Module
이때 GoogleNet이 제안한 아이디어는 전체 architecture는 최대한 sparse하게 쌓고 계산은 fully connected로 하는 개념이고 inception이라는 개념을 도입하고 1 x 1 Conv를 이용해서 구현을 진행한 것입니다.
일딴 inception모듈을 보게 되면 아래와 같습니다.
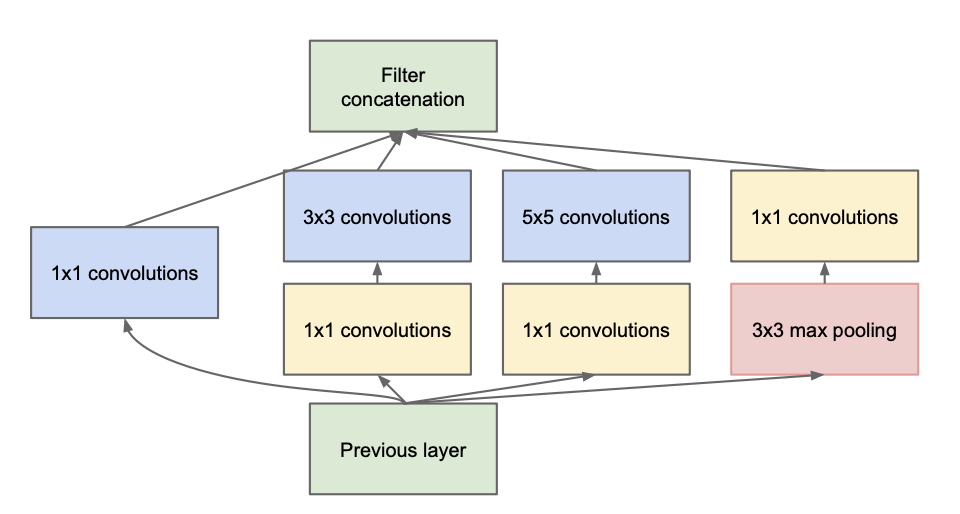
naive한 모델이 아니라 1x1 Conv layer를 쌓아서 만든 차원 축소를 가능하게한 module구조 입니다.
제가 생각한 비유를 들자면 인간을 기준으로 억배를 확대하면 세포가 보이고 10배 확보하면 모공이 보이려나? 그리고 2배 확대하면 인간 눈만 보이는 것처럼 다양하게 봐서 좋은 특징만 뽑아냅시다 뭐 이런 걸로 이해했습니다.
그리고 계산은 병렬적으로 하게 된다면 O(4n)이 아니라 O(max : n) 뭐 이렇게 계산 할 수 있지 않을까 하는 생각을 한 것 같습니다.
여기서 1 x 1 Conv layer가 하는 일은 차원 축소인데.. 이해를 해보자면 이전의 layer에서 넘어온 데이터를 1x1 Conv에 넣어서 max pooling을 해주게 되면 여러개의 채널을 하나로 압축해서 넘겨주기 때문에 연산량도 조금 줄 수 있는 효과가 있지 않나라고 생각했습니다.
결과적으로 논문 초반에 deep and wide라는 말을 했는데 wide는 일반적으로 한방향으로 깊게 쌓는 것이 아니라 넓게 쌓는 것인데 이에 대한 설명을 그림을 통해 해보자면 아래와 같습니다.
 위와 같이 Conv layer를 어떻게 쌓는 지에 따라서 추출해 낼 수 있는 정보가 다르게 되는데 이러한 layer 3개를 병렬적으로 쌓고 마지막에 채널을 합치게 함으로써 다양한 크기에 정보를 추출하고 학습할 수 있게 해줍니다.
위와 같이 Conv layer를 어떻게 쌓는 지에 따라서 추출해 낼 수 있는 정보가 다르게 되는데 이러한 layer 3개를 병렬적으로 쌓고 마지막에 채널을 합치게 함으로써 다양한 크기에 정보를 추출하고 학습할 수 있게 해줍니다.
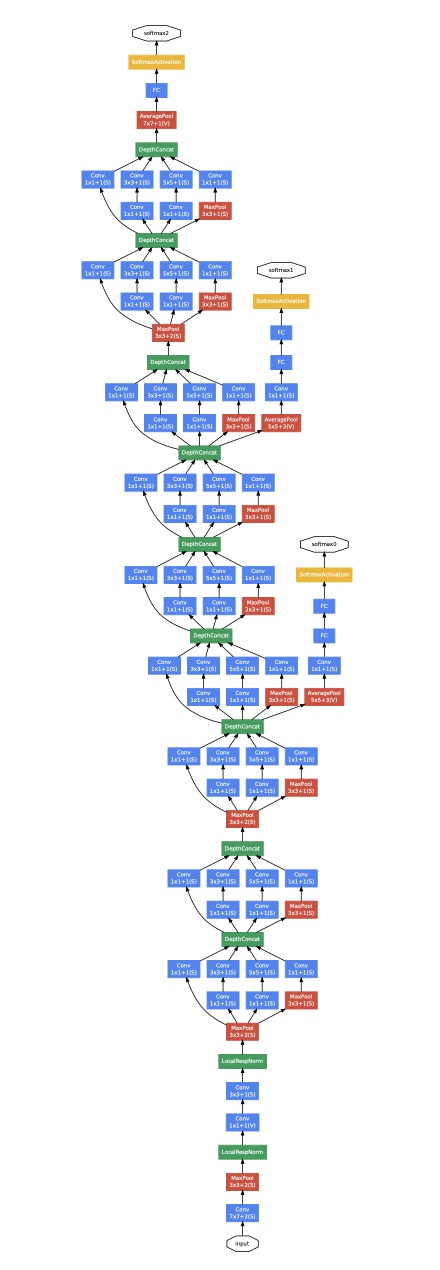
- Hole Architecture
전체 아키택쳐는 위에 그림과 같은데 (더럽게 기네) 사실 이부분은 아직 정확하게 이해가 잘 안됩니다. (블로그나 다른 글을 좀 읽고 정리해서 써보겠습니다. 추후에 뭐 수정 하겠죠)
처음 부분은 AlexNet의 구조를 따라갔다고 합니다. 그리고 input이 들어오는 시점에 이미지 사이즈가 가장 크기 때문에 필터로 이걸 전부 scan하게 되면 낭비가 심하게 될 것 같다고 예상한 것 같다고 합니다. (제 생각은 아직…)해서 큰 filter로 일딴 기를 죽여놓고 들어가서 inception module을 사용했다고 합니다.
이제 중간중간에 보이는 노랑색 분류기? 라고 하는 친구는 gradiant banashing문제를 없애기 위해서 넣은 장치라고 이해 했습니다. CNN은 깊게 쌓을 때 효과가 좋다고 가정했을때 (제가 공부한 ResNet은 아닌 것 같았습니다.) back propagation을 진행 했을 때 gradiant banishing문제가 생겨서 역전파가 잘 안되는 경우가 있을 수 있습니다. 이를 해결하기 위해서 중간에 중간다리를 놓아 두고 해당 지점 부터 역전파를 하게 되면 소실 되는 데이터를 줄일 수 있다는 어떤 해결 책으로 이해 했습니다.
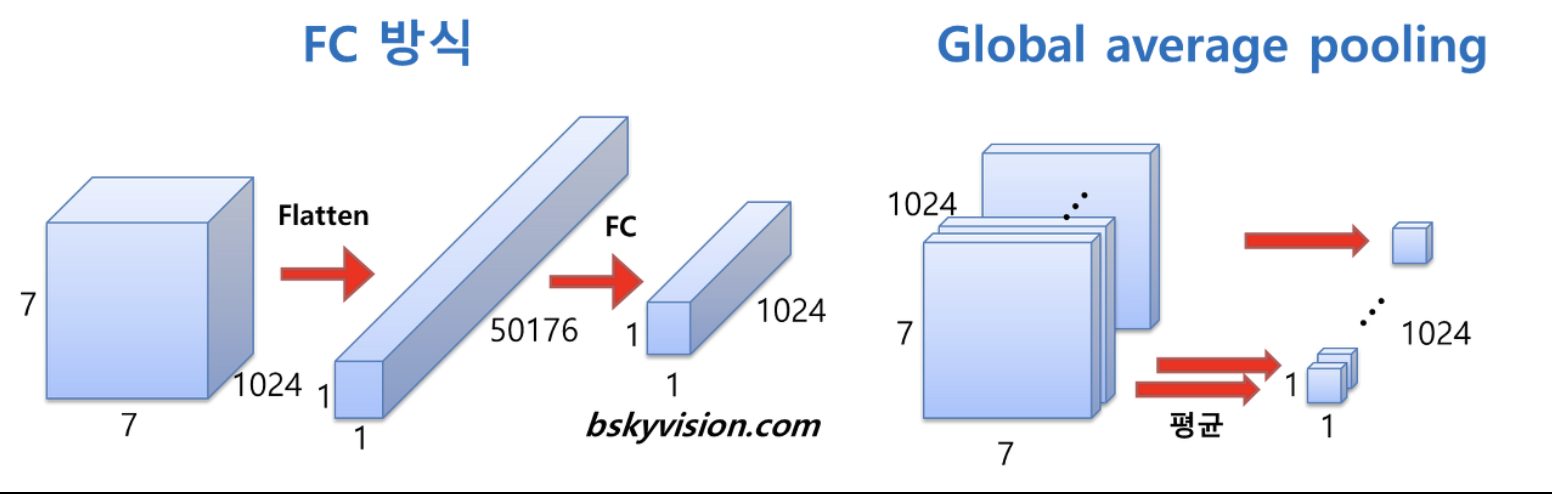 마지막 layer에서는 global Average pooling을 사용한다고 합니다. 제가아는 기존의 fully connected 방식은 HxWxC의 2차원을 11(HxWxC)로 Flatten시키고 이를 다시 fully Connected 해서 필요한 output을 만드는 작업으로 알고 있습니다. 하지만 global Average pooling은 각 채널마다 평균을 내게 함으로써 좀더 효율적으로 사용하게 하려고 하는게 아닌가 생각 해봅니다. (다른 블로그 에서는 성능향상보다는 finetunning의 용이성 때문이라고도 하네요)
마지막 layer에서는 global Average pooling을 사용한다고 합니다. 제가아는 기존의 fully connected 방식은 HxWxC의 2차원을 11(HxWxC)로 Flatten시키고 이를 다시 fully Connected 해서 필요한 output을 만드는 작업으로 알고 있습니다. 하지만 global Average pooling은 각 채널마다 평균을 내게 함으로써 좀더 효율적으로 사용하게 하려고 하는게 아닌가 생각 해봅니다. (다른 블로그 에서는 성능향상보다는 finetunning의 용이성 때문이라고도 하네요)
정리
논문을 처음 읽는 지라 사실 영어도 못하고 더듬더듬 찾아가면서 읽어 본것 같다. 레이어 쌓으면 끝아닌가 했던 막연한 생각들이 조금 정리가 된 시간인 것 같았다.
- googleNet에서 신기한점
- 뭔가 계속 layer에 딴짓을 하면 성능이 좋아질 수 도 있다는 생각을 해줬다.
- inception module에서 여러개의 Conv layer를 이용하는 어떤 철학? 같은걸 다르게 보는 눈을 가지게 하는게 신박했다는 생각도 했고
- back propagation을 막는 방법인 중간중간에 결과를 내는 것도 재밌었던 것 같다.
- 좀 더 생각해 봐야 하는 점
- 논문을 읽는 방법에 대해서 좀 배워보고 싶다.
- 그놈에 AlexNet과 Vggnet이 뭔지 알아야 겠다.
- Conv layer에 대한 명확한 이해를 하고 싶은데 referance가 있으면 좋곘다.
끝!