Abstract
이전 논문들에서는 Network 깊이를 늘리는 상황이 모델의 정확성을 높여주는 것에 대해 직접적으로 검증을 진행했다. 하지만 Network깊이가 깊어 짐에 따라서 vanishing gradient 문제와 overfitting 그리고 연산 비용의 여러 문제를 아직 해결하지 못하는 상황에서 ResNet은 이러한 문제를 최소화 하기 위해서 연구를 진행했다.
이러한 문제들을 해결하기 위해서 기본적으로 생각해 내내 아이디어는 기존에는 layer들을 어떤식으로 쌓던 간에 (내가 생각할 때) end-to-end방식으로 쌓아서 이러한 문제들이 발생했는데 해당 논문에서는 layer간 input을 참조해서 신경망을 구성했다. 여기서 residual function을 통해서 좀 더 깊게 쌓아 정확성을 올리는 것이 주된 목표 였다.
Introduction
Convolution Network를 이용한 많은 논문들이 나오게 되면서 이미지를 분류하는 작업은 굉장히 많은 발전을 이루어 냈다. VGG나 GoogleNet등 많은 모델이 나오게 되면서 정확성을 굉장히 올라가게 되었고 이러한 논문들을 통해서 layer를 더 깊게 쌓으면 더 높은 정확성을 얻을 수 있다는 것을 알게 되었다.
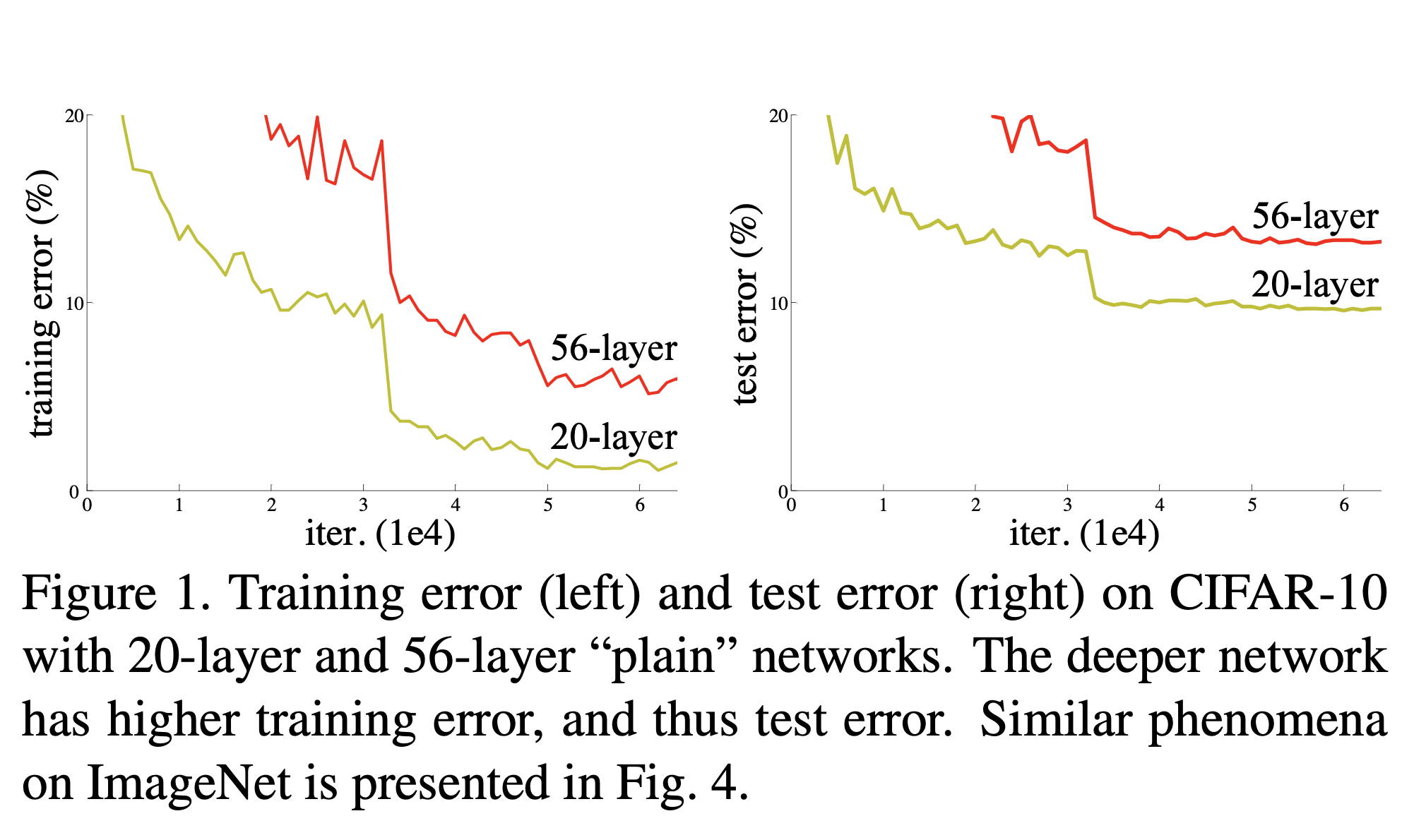
하지만 예상과는 다르게 당시 연구 결과들을 보게 되면 네트워크 깊이가 깊어 지면서 vanishing gradient문제가 생기게 된다. normalization같은 기법들을 통해서 어느정도 해결하는 모습을 보여주었으나 한계점은 분명하게 존재 하였다. 또한 아래의 그림에서 확인 할 수 있듯이 overfitting의 문제로 인해서 trainset과 testset에서의 괴리가 존재하고 layer를 더 높임에도 오히려 정확성이 더 떨어지는 모습을 볼 수 있었다.
해당 논문에서는 이러한 문제점을 해결하고자 조금 다른 방법을 사용하였다. 이전에 존재했던 많은 논문들은 input으로 이전 레이어의 x를 받아 H(x)를 내보내는데 논문에서 제시한 방법은 x를 목표로하는 y값 즉 H(x) - x = y가 되는 y값을 최소로하는 알고리즘을 만드는 것을 목표로 내세웠다. 이러한 개념을 residual function으로 부르고 입력과 출력의 차이를 최소화하는 y를 학습하면서 해당 문제를 해결하려는 방밥을 제시한 논문이 된다.
이러한 shortcut(논문에서 말하는 residual path??)을 통해서 backward propagation과정에서 vanishing gradient문제도 해결할 수 있고 이에 따라 네트워크 레이어의 깊이를 증가 시킬 수 있게 됨으로써 이전 보다 더 나은 정확성을 보여 줄 수 있었다.
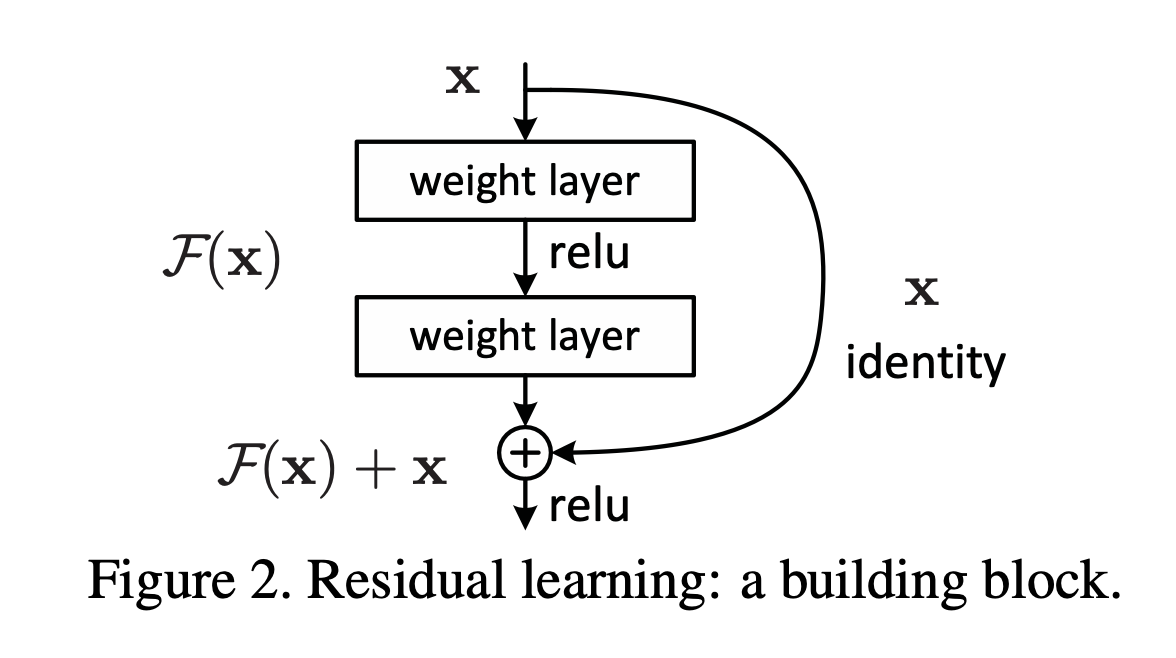
위의 그림은 residual function을 도식화한 그림인데 2개의 레이어를 건너 뛸 때 마다 indentity x값을 마지막에 더해줌으로써 해당 출력값과의 차이를 학습시키는 것을 볼 수 있다.
결과적으로 H(x) = F(x) +x 가 되면서 네트워크 구조도 크게 변경되지 않았고 이에 따라 파라미터 수의 변화가 없고 연산량 증가는 미비했다.
Related Work
-
residual representations
사실 이부분이 이해가 안된다…
-
shortcut Connections
위에서 언급한 shortcut Connection을 구성하기 위한 다양한 사례에 대해서 소개를 하는데 이때 ResNet의 shortcut connection은 파라미터가 추가되지 않고 해당 값이 0으로 수렴할 수 없기 때문에 정보를 항상 내보낼 수 있다고 한다. 이러한 이유로 지속적으로 residual function을 학습하는 것이 가능하다고 이야기 한다.
Deep Residual Learning
-
Residual Learning
앞쪽에서 언급한 residual learning은 input layer의 값과 output layer의 차이를 학습시키게 하는 데 실제로는 학습시키는 값이 최적인 경우는 매우 희박다하고 한다. 하지만 이러한 방식은 문제에 pre-conditioning을 추가하는데 도움을 준다고 한다. 따라서 pre-conditioning으로 인해 Optimal function이 zero mapping보다 identity mapping에 더 가깝다면, solver가 identity mapping을 참조하여 작은 변화를 학습하는 것이 새로운 function을 학습하는 것보다 더 쉬울 것이라고 마이크로소프트팀은 주장 한다. 라고하는데 좀 더 쉽게 이해 할 수 있는 말이면 좋겠다!
-
identity mapping by shortcuts
이부분을 내가 이해해본대로 써보자면 input x는 Conv. layer를 거치면서 차원이 달라질 수 있는 가능성이 생기게 된다. 이때는 linear projection인 Ws를 곱하여 차원을 같게 만들어 줄 수 있다고 한다.
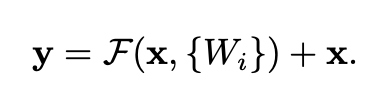
Architecture
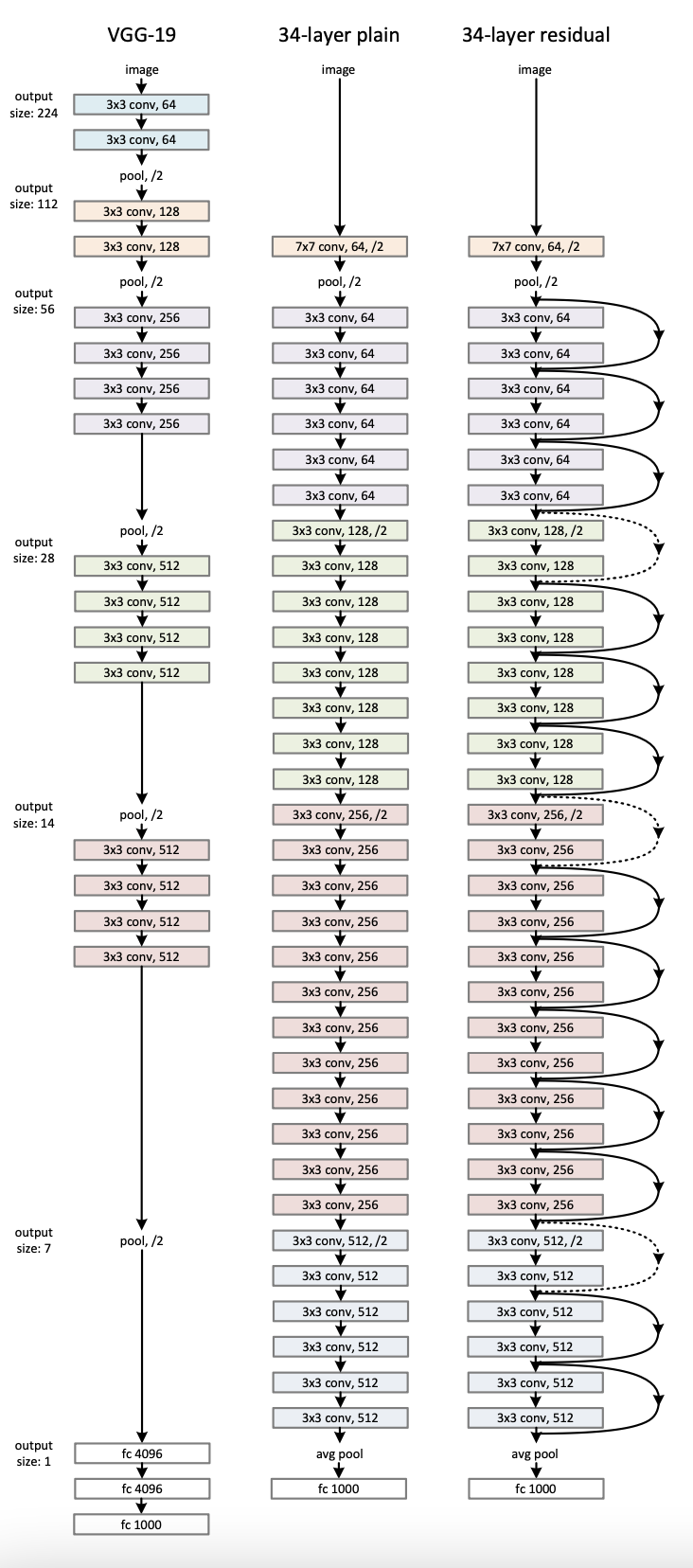
기본적으로 baseline 모델로 사용한 plain net은 VGG에서 영감을 받았다고 한다. 전체 Conv filter size가 3x3이 되고 Output feature map size가 같은 layer는 모두 같은 수의 conv filter를 사용했고 feature map이 절반으로 줄면 time complexity를 동일하게 유지 하기 위해서 필터수를 2배로 늘려주었다.
만약 차원이 줄어서 identity shortcut을 바로 사용할 수 없게 된다면, 첫번째로 zero padding을 적용해서 차원을 키워줄수 있고 projection shortcut을 사용할 수 있다. 이 때 projection shortcut은 1x1 conv layer를 통해서 차원을 맞춰주는 역할을 한다.
Implementation
- augmentation을 위해서 짧은 쪽이 256이 되도록 랜덤하게 resize를 진행
- Horizontal filp을 랜덤하게 적용 및 zero-mean centered 적용
- 각 convolution마다 batch normalization진행
- He 초기화 방법으로 가중치 초기화
- SGD사용
- learning rate : 0.1
- weight decay : 0.0001
- Momentun: 0.9
- epoch 60x10
- drop out을 사용하지 않음
Experiment
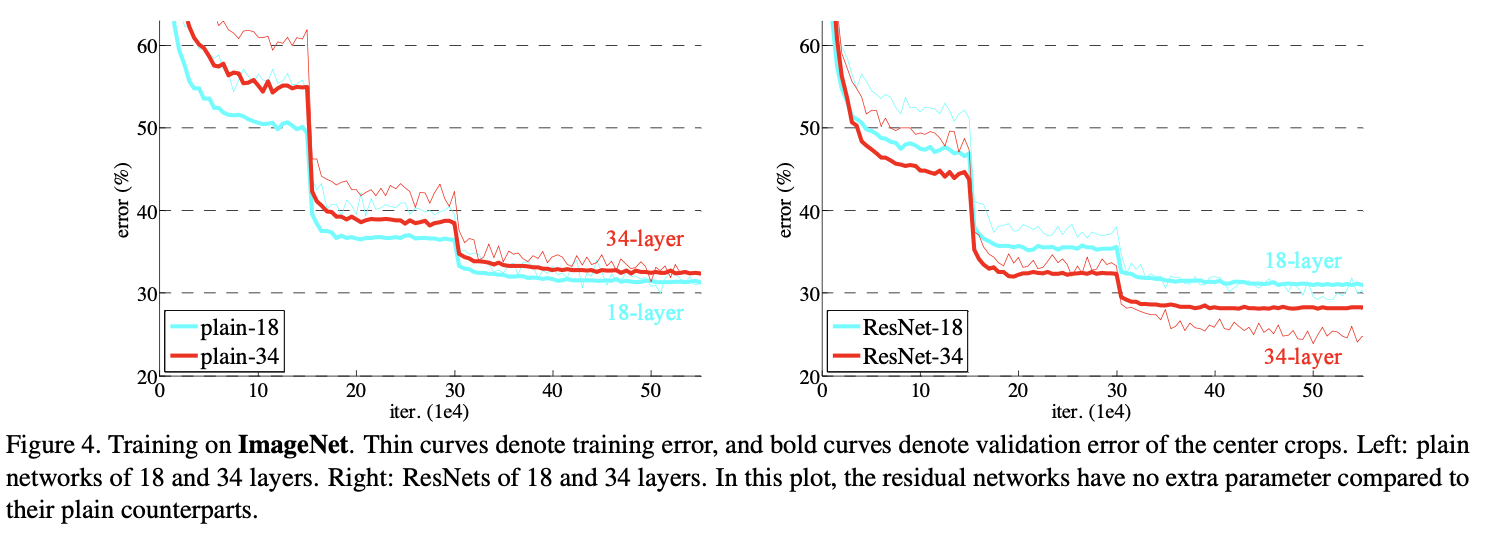 결과적으로 보게되면 더 깊이 쌓아서 더 좋은 성능을 내는 것을 확인해 볼 수 있다. plain layer일 떄는 더 깊게 쌓을 수록 더 안좋은 결과를 내는 것을 볼 수 있지만 ResNet은 layer를 더 깊게 쌓으면 확실히 errer가 줄어드는 것을 볼 수 있다.
결과적으로 보게되면 더 깊이 쌓아서 더 좋은 성능을 내는 것을 확인해 볼 수 있다. plain layer일 떄는 더 깊게 쌓을 수록 더 안좋은 결과를 내는 것을 볼 수 있지만 ResNet은 layer를 더 깊게 쌓으면 확실히 errer가 줄어드는 것을 볼 수 있다.
identity vs Projection Shortcuts
여기서는 해당 실험 이후에 projection shortcut에 대해서 비교실험을 진행하였다.
- zero-padding shortcut을 사용한 경우에
- projection shortcut을 사용한 경우, 차원이 축소될때 만 (다른 모든 shortcut은 identity)
- 모든 shortcut으로 projection shortcut을 사용한 경우
이 때 3가지 모두 plain model보다 좋은 성능을 보였지만 그 성능차이가 미미 했기 때문에 해당 튜닝은 필수적이지 않다는 것을 확인 할 수 있었다고 한다.
Bottleneck Architectures
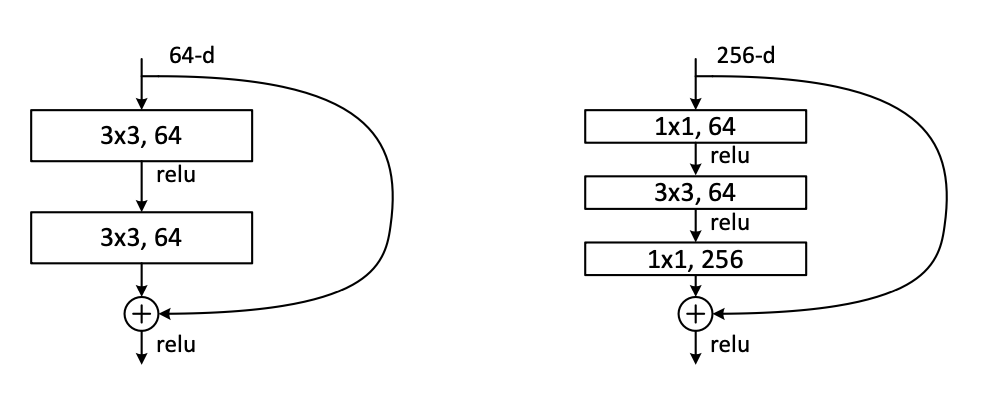
layer가 50개가 넘어가면서 부터는 bottleNeck block에 1x1 Conv. layer를 추가해서 layer의 갯수는 증가하지만 parameter 개수는 증가되게 만들어 computational cost가 감소하는 효과를 가져올 수 있게 하였다.
이런거 보면 1x1 Conv layer를 쓴 googleNet이나 VGG나 어마어마 한 영향을 미쳤다고도 생각할 수 있다.