우리는 배가 고프다.
일전에 배운 Unit2에서는 value-function과 이를 통해 나오는 결과물인 Q-table을 학습시키는데 중점을 두었다면 이번에 중요한 부분은 과연 이게 현실 가능한 거냐?에 대한 부분이다.
예시로는 쥐돌이 게임을 통해서 생각을 해보았지만 문제는 실제 생황에 적용을 하려면 scalable하지 않다는 것이다. 즉 너무 많은 파라미터를 가지게 되면 당연히 결정적인 시간안에 예측을 할 수 없을 것이고 결국 의미 없는 알고리즘이 될 것이다.
보통 게임을 만드는데 있어서 Convolution Neural Network로 학습을 하게되면 생기는 문제는 예를들어 size가 160 x 210에 3채널을 가지고 있다면 해당 파라미터의 수는 256 ^(210 * 160 * 3)가 되면서 굉장히 많은 수의 parameter를 가지게 되고 이는 결국 계산할 수 없다는 것에 이르른다.
그렇다면 어떻게 이런 문제를 해결할 수 있을까?
뭐 이런 일이 있을 때 컴퓨터 사이언스 쪽에서는 항상 approximate하게 문제를 해결하려고 한다. 정확한 값을 알 수 없는 상황이라면 현재의 computing 리소스를 가지고 정답에 가장 근사할 수 있는 방법을 찾고 이를 implimentaion하여 결과로 쓰는 방법을 택한다. 그럼 이번장에서는 이를 한번 배워보자.
DQN
이번장에서 배우는 DQN은 Deep Q-Network의 약어이다. 다른게 중요한 것이 아니라 어떻게 정답에 근사한 값을 낼 수 있는 가에 대한 이야기 이다.
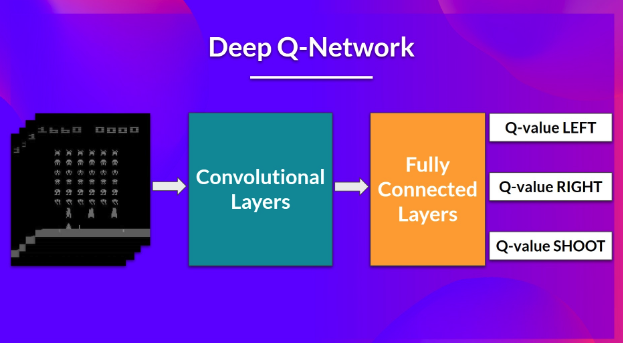
구조는 간단하다. 4개의 frame을 input으로 주고 convolutional Layer에 넣고 flatten시킨뒤 이를 통해 하나의 action을 추출해 내는 것을 기본으로 한다.
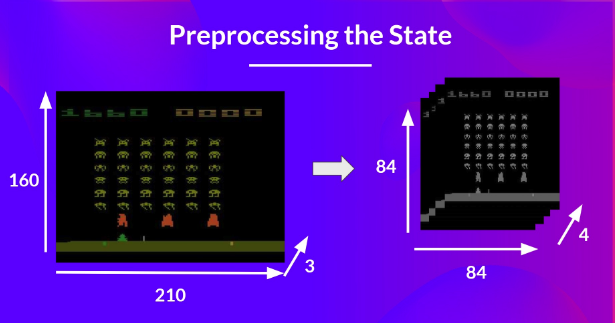
글에서는 Preprocessing을 중요하게 여기는데 이는 input을 조금이나마 줄이려는 의도를 가진다. 이런 논리는 다움과 같다.
- 중요한 정보는 색정보가 아니다 -> RGB 3채널 보다는 4개의 frame으로 channel을 바꾼다.
- 채널이 4개인 이유는 연속성 속에서 어떤 데이터를 얻기 위함이다.
- 단 하나의 장면만 보고 어떤 선택을 하는 것을 굉장히 위험한 일이다.
- 하지만 여러개의 데이터를 놓고 보면 현재 상황을 좀 더 정확하게 유추할 수 있으므로 4개정도의 frame을 사용한다.
- W와 D는 raw 데이터일 필요는 없다.
- 흑백이나 색갈이나 크게 다를 것이 없는 것은 자명한 일이기 때문이다. 다음의 DQN Algorithm에 관한 이야기이다.
Deep Q-Learning Algorithm
일전에 봤던 수식을 다시쓰면 이렇게도 쓸 수 있다.
결국 현재 state에서 Action을 선택할 때 가장 좋은 reward를 선택할 수 있는 어떤 action을 찾는 일이다.
여기서 우리의 목표값은
가 된다. 즉 어떤 선택을 했을 때 해당 선택이 가져다 주는 reward와 엑션을 취한 후 다음 state에서 가질 수 있는 최대 Q-value값의 합이 Q-Target이 된다. 이렇게 되면 우리가 가지는 Q-Loss는 아래와 같게 된다.
이때 Q-Learning의 algorithm은 2가지 phase를 가진다.
- Sampling : action과 observed experience(State)의 tuple을 replay memory에 저장하는 것
- Traning : Sampling된 replay memory에 작은 batch를 선택하고 이를 이용해 backpropagation 및 weight 업데이트를 진행하는 작업