혼자 울면서
1. Overview & IDEA - PPT Searching 2. Extracting with PPT 3. TF-IDF with PPT 4. Threading with PPT 5. Operating with PPT
TF-IDF
내가 이해하는 TF-IDF 알고리즘은 아래와 같다.
- TF(Term Frequency) : 단일 문서 내에서 특정 키워드의 등장 빈도
- IDF(Inverse Document Frequency) : 문서군 내에서 특정 키워드가 등장한 문서의 개수의 역수
- TF-IDF : TF와 IDF를 곱하게 되면 문서군내에 해당 문서에서 각 키워드가 얼마나 중요한지를 나타내는 값을 얻을 수 있다.
이를 통해서 우선 특정 폴더를 대상으로 추출을 한뒤 비교 분석을 조금 해보았다.
사실 TF-IDF를 직접 구현 하려고 했지만 시간상 sklearn을 사용했다. 다만 추후에 설명할 수 있겠지만 TF-IDF모듈을 잘 뜯어보면 CountVectorizer()와 같은 객체를 통해서 실제 갯수를 볼 수도 있다. 이를 통해 운영 단계에서 최적화를 할예정이 있었다. (하지만 선임의 반대로 구현까지 할 수 는 없었다는건 안비밀… ㅠㅠ)
def tfidf_cal_func(folder_path="./", min=2, output_name="output", ngram=None):
extract_text_df = pd.DataFrame(
list(PRE.folder2data(folder_path).items()), columns=["location", "keyword"]
)
keyword = extract_text_df["keyword"].tolist()
location = extract_text_df["location"].tolist()
if ngram is None:
tfidf_vectorizer = TfidfVectorizer(min_df=min)
else:
tfidf_vectorizer = TfidfVectorizer(min_df=min, ngram_range=ngram)
# 후처리 코드
tfidf_vectorizer.fit(keyword)
# TfidfVectorizer에 vocabulary라는 코드가 전체 키워드를 리턴해준다.
word_id_list = sorted(
tfidf_vectorizer.vocabulary_.items(), key=lambda x: x[1], reverse=False
)
word_list = [x[0] for x in word_id_list]
tf_idf_df = pd.DataFrame(
tfidf_vectorizer.transform(keyword).toarray(), columns=word_list
)
# reverse는 키워드를 row로 가져오기 위한 방법이었고 해당 키워드의 문서군내 weight를 적어 주었다.
reverse_tf_idf_df = tf_idf_df.transpose()
text_ranking_dict = {}
for num in range(0, len(location)):
temp = reverse_tf_idf_df[num].sort_values(ascending=False)
temp_index_list = temp.index.tolist()
text_ranking_dict[location[num]] = temp_index_list
text_ranking_dict[location[num] + " weight"] = temp.tolist()
result_data = pd.DataFrame(text_ranking_dict)
result_data.to_csv("./" + output_name + ".csv", encoding="utf-8-sig")
return result_data
이부분이 TF-IDF를 계산하고 적절한 후처리를 통해서 엑셀에 row : 문서, column : 단어를 낸 결과이다.
- folder2data함수를 이용해 DataFrame 추출해낸다.
- 이후 N-gram을 통해서 정확성을 조금 더 올리려고 한 부분이 있다.
- 당시 시간이 남은게 아니라 특정 단어들에서는 2개의 단어를 이어 붙였을 때 성능이 조금 더 좋아져서 해당 option을 붙인 기억이 있다.
- 이렇게 한뒤 적절한 후처리를 거쳐서 csv로 뽑아낸다.
이러한 결과물에 사진이 없는 이유는 보안 때문이다. 해당 프로젝트 들이 회사에 있는 전체 데이터를 가지고 진행되었고 해당 데이터들은 내부 기밀이기 때문에 들고 나올 수 없다
그리고 아래는 조금 다른 코드인데 main함수를 만들어서 sys변수를 만들고 이에 따라서 프로그램을 구동할 수 있고 help를 만들어서 지속적으로 사용할 수 있게 프로그래밍했다.
explain_txt = """
This program will extract keyword from text
there are four options
1. folder_path
COMMAND INPUT : -i [folder_path]
DEFAULT VALUE : ./
input is set target folder extract keyword from "only" pptx
program run on recursivly track the folder and fun all child folder
2. min : -m [minimun number about existing keyword]
COMMAND INPUT : -m [minimun number]
DEFAULT VALUE : 2
About keyword this will take the threshold for keyword Count
3. output_name
COMMAND INPUT : -o [output_path]
DEFAULT VALUE : output
output_name will run for excel
4. ngram
COMMAND INPUT : -n [ngram max number]
DEFAULT VALUE : None
if you want to take the ngram algorithm in tfidf this will be parameter for ngram"""
if __name__ == "__main__":
print(sys.argv)
if ("-h" in sys.argv or "-help" in sys.argv or "h" in sys.argv) and len(
sys.argv
) == 2:
print(explain_txt)
else:
input_name = "./"
min_val = 2
output_name = "output"
ngram = None
if "-i" in sys.argv:
input_name = sys.argv[sys.argv.index("-i") + 1]
if "-o" in sys.argv:
output_name = sys.argv[sys.argv.index("-o") + 1]
if "-m" in sys.argv:
min_val = sys.argv[sys.argv.index("-m") + 1]
if "-n" in sys.argv:
ngram = (1, int(sys.argv[sys.argv.index("-m") + 1]))
start = time.time()
print("*" * 50, "root folder {} extrating start".format(input_name), "*" * 50)
tfidf_cal_func(
folder_path=input_name,
min=int(min_val),
output_name=output_name,
ngram=ngram,
)
print("*" * 50, "root folder {} extrating end".format(input_name), "*" * 50)
end = time.time()
print("total extrating time : {} sec".format(end - start))
Result
결과를 보기에 앞서서 프로그램 구동시 고려해야할 점에 대해서 언급해보자
앞서서 이야기 했듯이 건축과 건축이외의 공정에 어느정도 연관이 있는 상황이다. 이를 TFIDF에 적용을 하기 위해서는 2가지가 고려되야한다.
- 어디까지를 문서군으로 정의할 것인가?
- 공종간에 관계가 실제로 유의미하게 차이가 나는 것인지?
위의 2가지는 성능에서 유의미한 차이를 보일 수 있는 가능성이 존재한다. 해서 총 2가지 실험을 진행했다.
대분류 vs 소분류
프로젝트가 아니라 쌓여있는 DB를 기준으로 보았을 때 폴더 트리는 그 깊이가 깊을 수도 깊지 않을 수도 있다. 하지만 TFIDF는 분명 문서군이라는 걸 기준으로 그 역수값을 계산한다. 해서 가중치를 계산하는 집단의 크기가 분명 중요해 보였다.
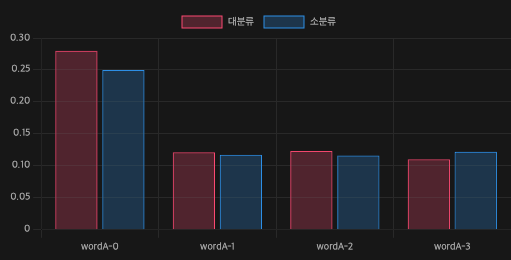
문서에서 이름조차 정확하게 보여줄 수 없는 상황이지만 어쨌든 비슷한 단어들에 대해서 문서군이 좀더 큰 상황에서 분명 유의미하게 가중치의 차이가 있는 것으로 보여진다. 하지만 크게 차이가 없는 것 또한 볼 수 있다.
공종별 문서 비교
이 부분이 설명하기가 좀 어려운 부분인데 이런 가설이 있다고 생각하면 좋을 것 같다.
건축은 범용적으로 사용하는 언어들이 많기 때문에 특정 건축용어에 대해서는 가중치가 유의미 하지 않을 수 있다. 하지만 건축 이외의 공종은 좀 더 전문적인 내용이 문서에 담기면서 좀 더 구분하기가 쉬워질 것이다. 해서 나온 결과는 아래와 같다.
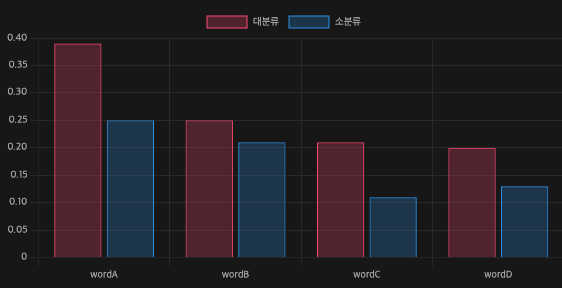 위에 그래프 처럼 공종이 특정된 문서에서 각기 다른 단어들에 대한 대분류 체계에서의 가중치 값은 유의미 하게 높은 것으로 보여진다.
위에 그래프 처럼 공종이 특정된 문서에서 각기 다른 단어들에 대한 대분류 체계에서의 가중치 값은 유의미 하게 높은 것으로 보여진다.
이를 통해서 내릴 수 있는 결론은 아래와 같다.
소분류보다는 대분류가 더 의미 있는 문서군이며 특히 같은 문서군 내에서도 건축에 관련된 문서보다는 특정 공종에 관련된 문서군이 더 유의미한 차이를 가진다.
여기까지의 결론으로 선임분을 설득 시킬 수 있었다. 각 문서군과 공종에 따라서 분류를 어느정도 다시 진행해야하고 이를 통해서 나온 가중치 값으로 문서를 정렬해야한다! (선임님은 설계를 오래하신 분이지만 높은 인사이트로 프로젝트를 보고 계셨다. 코드는 아예 모르셔도 인사이트가 대단했던 것 같다.)
->다음편4. Threading with PPT에서 계속
1번 그림 차트
type: bar
labels: [wordA-0, wordA-1, wordA-2, wordA-3]
series:
- title: 대분류
data: [0.28,0.121,0.123,0.11]
- title: 소분류
data: [0.25,0.117,0.116,0.122]
tension: 0.47
width: 80%
labelColors: false
fill: false
beginAtZero: true
bestFit: false
bestFitTitle: undefined
bestFitNumber: 02번 그림 차트
type: bar
labels: [wordA, wordB, wordC, wordD]
series:
- title: 대분류
data: [0.39, 0.25,0.21,0.2]
- title: 소분류
data: [0.25,0.21,0.11,0.13]
tension: 0.2
width: 80%
labelColors: false
fill: false
beginAtZero: true
bestFit: false
bestFitTitle: undefined
bestFitNumber: 0