Abstract
해당 논문은2018년 정도에 나온 논문으로 앞서 공부했던 논문보다 좀 더 늦게 나온 논문이라고 할 수 있다.
해당 모델에 가장 중요한 점을 꼽자면 이전 모델들은 이전 레이어에서 바로 다음 레이어만 연관을 가지게 하면서 parameter를 전달했다. 하지만 해당 논문은 1개의 레이어에 대해서 이후 레이어에 모두 연관 되게 진행하는 모델을 만들어냈다.
이러한 모델에는 여러가지 이점이 존재하는데 이는 아래와 같다.
- vanishing-gradient 문제를 줄일 수 있다.
- feature propagation이 강화 된다.
- 이전 feature를 다시 사용할 수 있다.
- parameter의 수를 줄일 수 있다.
Introduction
-
Problem
해당 시점에 마주친 문제점은 역시 깊이가 깊어 질 수록 vanishing-gradient문제가 생긴다는 것이고 이로 인해서 information이 wash out된다는 것이다.
이를 위해서 ResNet은이나 Highway Network는 다음 레이어로 들어가는 파라미터를 변화 시켰고 Stochastic depth은 dropping layer를 (내가 생각하는 것은 dropout 개념) 이용하기도 하고 fractalNet은 반복적으로 병렬적인 레이어를 만들어서 다른 파라미터를 전달 받는 개념을 이용하기도 했다.
하지만 이런 모델들의 기본적인 개념은 이전 레이어와 이후 레이어의 1:1 대응으로 문제를 해결했다는 점이다.
-
Solution
해당 논문의 필자들은 이런 잡다한 것 다 치워버리고 아주 간단한 architecture를 통해서 문제를 해결하자는 것이다.
기본적인 아이디어는 L개의 레이어가 존재한다면 l번째 레이어는 l * (l +1) /2 개의 input을 가지면서 이전에 학습한 parameter를 전부 연결시키는 개념이다. (조합의 개념으로 이해하면 쉽다.)
이러한 개념의 모델을 만드려면 직관적으로 굉장히 적은 parameter를 가지고 있어야 가능할 것 같다고 이야기 한다.
-
ResNet에 뭐 원한이 있나?
해당 논문에서는 ResNet을 기존의 패러다임으로 보고 이를 비판하면서 본인의 모델이 좋다고 이야기하는 느낌을 받았다.
모델은 ResNet은 특징을 적게 가져갈 수 밖에 없는 구조(실제 뽑은 parameter라기 보다는 input과 학습한 값의 차이점을 학습하는거니까)를 가지고 있다고 이야기 하고 각 paramenter가 넘어가고 더해지면서 더 커진다고 한다.
-
DensNet?
해당 모델은 더 적은 parameter를 점기면서 여러개의 얕지만 많은 정보를 가질 수 있다고 이야기한다. 이를 통해서 information을 더 많이 전달 수 있고 gradient 또한 좀 더 잘 전달 할 수 있다고 이야기 한다. 또한 이전 레이어들이 전부 연결되어 있게 되면서 loss function에 이전 레이어의 정보들이 들어갈 수 있다고 생각하고 이를 통해서 Overfitting이 줄어들 수 있게 되었고 적은 trainSet으로 학습이 가능하다고 생각했다.
Related Work
해당 절에서는 이전의 연구들과 동시대 혹은 이전시대에 나왔던 모델들에 대한 특징을 나타내고 있다.
- 이전에도 이러한 문제 (information이 적절하게 전달되지 않는 문제)를 해결하기 위해서 많은 노력이 있었다고 이야기 한다.
- Highway Network는 bypassing을 하면서 100개이상의 레이어를 만들어 냈고 이를 통해서 좀더 쉽게 학습을 진행 할 수 있게 한다고 했다.
- ResNets은 residual block을 통해서 이전 레이어와의 차이점을 학습하지만 이는 정보를 정확히 전달 할 수 없다고 이야기 한다.
- Stochastic depth은 bypassing하면서 좀더 쉽게 학습을 할 수 있다고 이야기 한다.
위의 세가지 경우는 레이어를 deep하게 쌓는 방식에서의 여러 방법에 대한이야기를 한다.
레이어를 다른 방식 (orthogonal한 접근)으로 깊게 쌓는 방법은 googleNet처럼 여러개의 레이어를 병렬적으로 학습시키고 이를 합치는 방식이다.
- DesNet은 여기서 다른 방법을 사용하는데 이전에 레이어에서 찾아낸 feature를 다시 input 레이어로 넣어주어서 학습시키는 것이다. 중요한 것은 이러한 방법이 병렬적으로 레이어를 쌓아서 다시 합치는 비효율적인 방법을 사용하는 것이 아니라 직관적이고 더 적은 parameter를 사용하는 방법이라고 이야기하고, resNet과 다른 중요한 차이점을 이야기 한다고 얘기한다.
DenseNets
해당절에서는 densenet의 구조에 대해서 이야기 한다.
최초의 단일 이미지인 x0가 존재하고 레이어는 L개의 레이어를 이용한다. 이후 non-linear transformation Hl(.)를 이용하는데 이는 batch normalization → ReLU → Conv.로 구성이 되어있다.
- Dense connectiviyt는 아래와 같은 수식을 가진다.
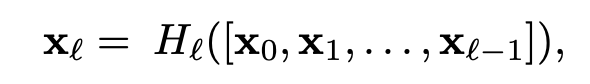
해당 수직은 l번째 레이어에 feature를 만들기 위해서 이전에 모든 레이어에 transformation을 취한다는 이야기를 한다. 이를 통해서 이전에 존재하는 feature를 잡아올 수 있다,
-
Composit function
이절에서 Hl(.)는 batch normalization → ReLU → Conv. 3x3을 사용한다고 한다.
-
Pooling layer
pooling layer에서는 1x1 Conv layer와 이 뒤에 따라오는 2x2 average pooling layer를 통해서 연산수를 줄일 수 있게 해준다고 이야기한다.
-
Growth rate
여기에서는 좀 특이한 개념이 등장하는데 Hl이 k개의 feature map을 만들어 낸다면 l번째 레이어는
k0 = k x (l-1)의 input을 가진다고 이야기한다. 이때 DenseNet의 가장 특이한 점은 hyperparameter인 k를 12로 사용하면서 굉장히 narrow한 layer를 쌓는다고 이야기한다.
또한 이러한 레이어를 통해서 해당 레이어는 이전에 가졌던 모든 feature-map을 가지고 있게 되고 이를 해당 레이어가 global state of network를 가지고 있다고 이야기한다.
이는 다른 모델에 비해서 중복이 존재하지 않고 각 레이어에서 이전 레이어의 모든 feature-map에 접근 할 수 있다는 것을 이야기한다.
-
Bottleneck layer
각 레이어가 k개의 feature-map을 output으로 내기 때문에 이 보다 큰 input크기가 존재하게 된다면 1x1 Conv. layer와 3x3 Conv. layer를 통해서 input을 맞춰 준다고한다. 해서 Hl(.) = BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)으로 치환하고 이를 DensNet-B라고 명명한다.
-
Compression
더 압축된 feature-map을 가진 레이어를 만들기 위해서 만약 dense-block이 m개의 feature-map을 가지고 있다면 thm의 output으로 만들게 된다. 이때 th는 0<th<1값을 가지면서 th = 0.5일때 DenseNet-BC라고 명명한다.
Dataset
CIFAR10, CIFAR100
SVHN (the street view house number)
ImageNet
Traning
Result
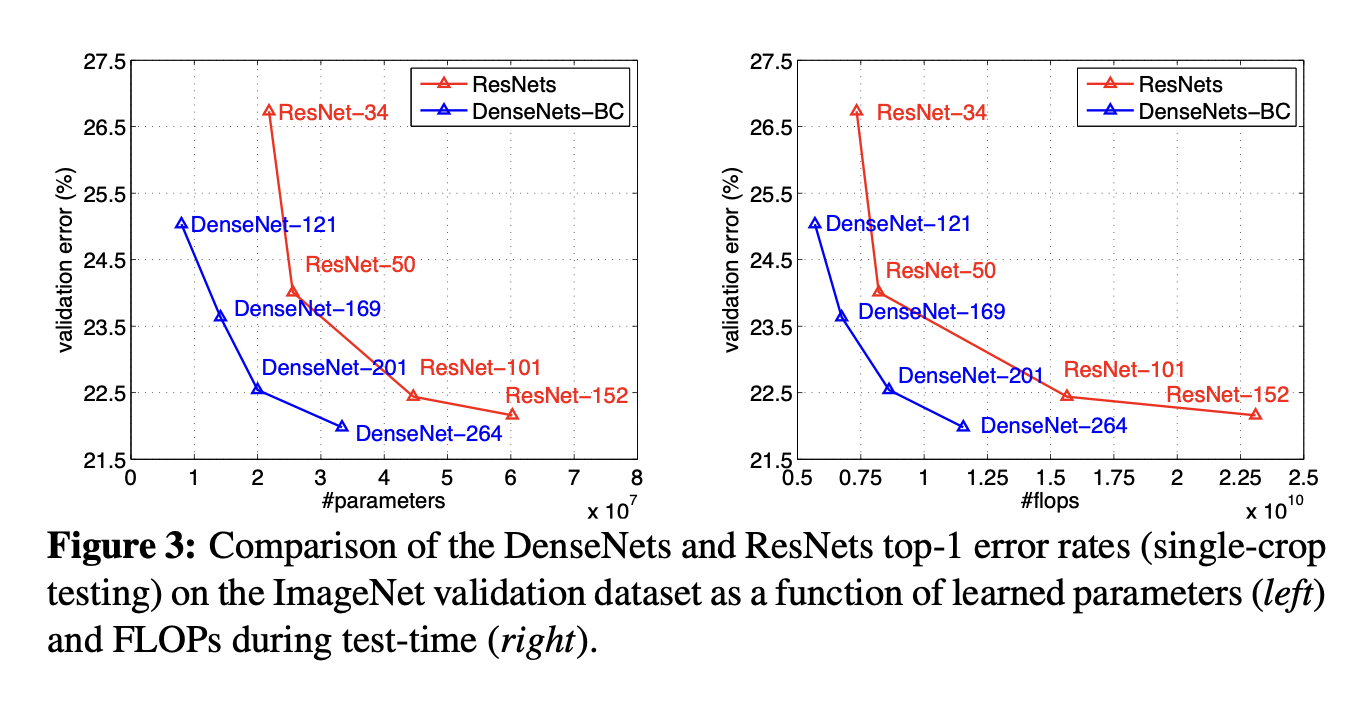
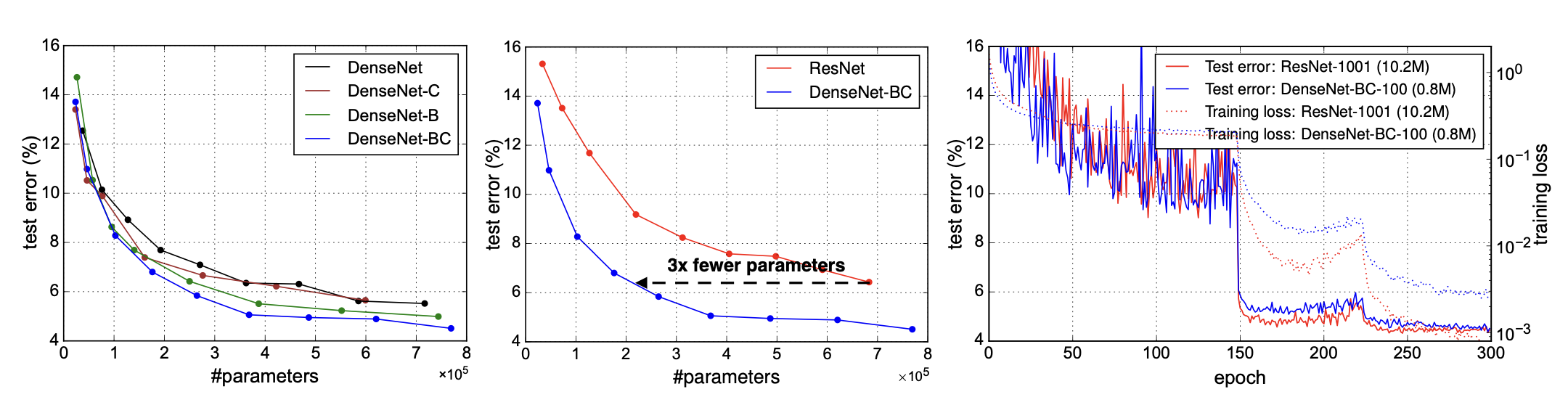
Discussion
-
model compactness
denseNet은 resnet과 굉장히 유사한 모습을 보이지만 위의 그래프에서 볼 수 있 듯이 3배더 적은 파라미터수를 가지고 같은 성능을 낼 수 있는 모습을 보여준다.
-
Implicit Deep Supervision
loss function에 이전에 feature가 들어가게 되면서 추가적인 supervision을 받는다고 이야기 한다. ??
-
Stochastic vs Deterministic connection.
-
Feature reuse
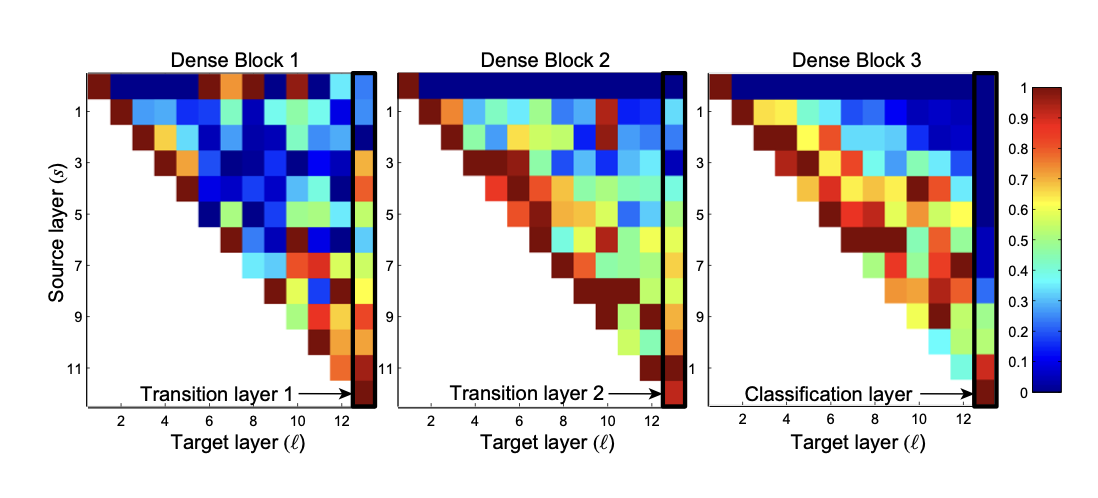
해당 그래프는 블록내에서 각 레이어들의 평균가중치를 나타낸 것을 볼 수 있는데 l,s의 레이어는 이전 레이어의 정보를 비슷하게 이용하는 것을 보여줄 수 있다.
Conclusion
내가 생각한 DenseNet은 이전에 존재하는 많은 모델의 구조를 가장 간단하게 나타냄과 동시에 유의미한 성능 발전을 보여주었다고 생각한다.
한 세기를 rap-up했다는 생각도 들고 이를 통해서 좀 더 직관적으로 깊고 넓은 network를 쌓는 방법을 제시했다고 볼 수 있다.
다만 이러한 방식은 하드웨어와 소프트웨어가 몇년사이에 비약적으로 발전하면서 이룰 수 있는 논문이지 않았나 생각한다.