DBMS
많이들 DBDB한다 하지만 정작 DB가 뭔가라고 물어보면 제대로 대답할 수 있는 사람이 많이 없을 수 있다. 데이터를 저장할 수 있는 어떤 파일은 모두 DB가 될 수 있을 것이다. txt, csv, json, parquet과 같은 많은 파일 형식이 있다. 이중에서 CS에서 사용하는 DB는 뭘까?
DBMS = DataBase Managing System이다. 일딴 Managing System이 들어갔다는 이야기는 데이터베이스를 관리하는 체계라는 이야기다.
그렇다면 그냥 txt나 csv로 저장해도 되면 되지 왜 DBDB거리면서 이걸 만드냐라고 보면 간단하다. 데이터베이스에서 누가 저장을 했는데 갑자기 다른 데이터가 변경된다거나 갑자기 다른데이터가 삭제된다거나, 혹은 읽었는데 내가 예상하지 않은 값이 나온다거나 이런 많은 문제를 체계적으로 관리가기 위해서 약속된 어떤 System을 만들어 놓은것이다.
Record
그럼 실제로 데이터 베이스에 저장되는 건 뭘까? 문자열 일까? 라는 궁금증이든다. 책에서는 Record라는 용어를 사용한다.
그럼 저장되는 최소단위가 Record라면 이는 어디에 저장이 되는 것이지? 라는 생각을 좀더 해보자. 2가지 Level로 움직일 수 있는데 물리적 환경과, 논리적 환경으로 이해를 해볼 수 있다.
물리적 환경
레코드는 디스크에 저장이 된다. 요즘 컴퓨터를 사는 사람들은 이해할 수 없지만 예전에 모니터 뒤가 뚱뚱한 컴퓨터를 써본 사람들이라면 하드디스크를 들어본적이 있을 것이다. 이친구는 아래와 같이 생겼다.
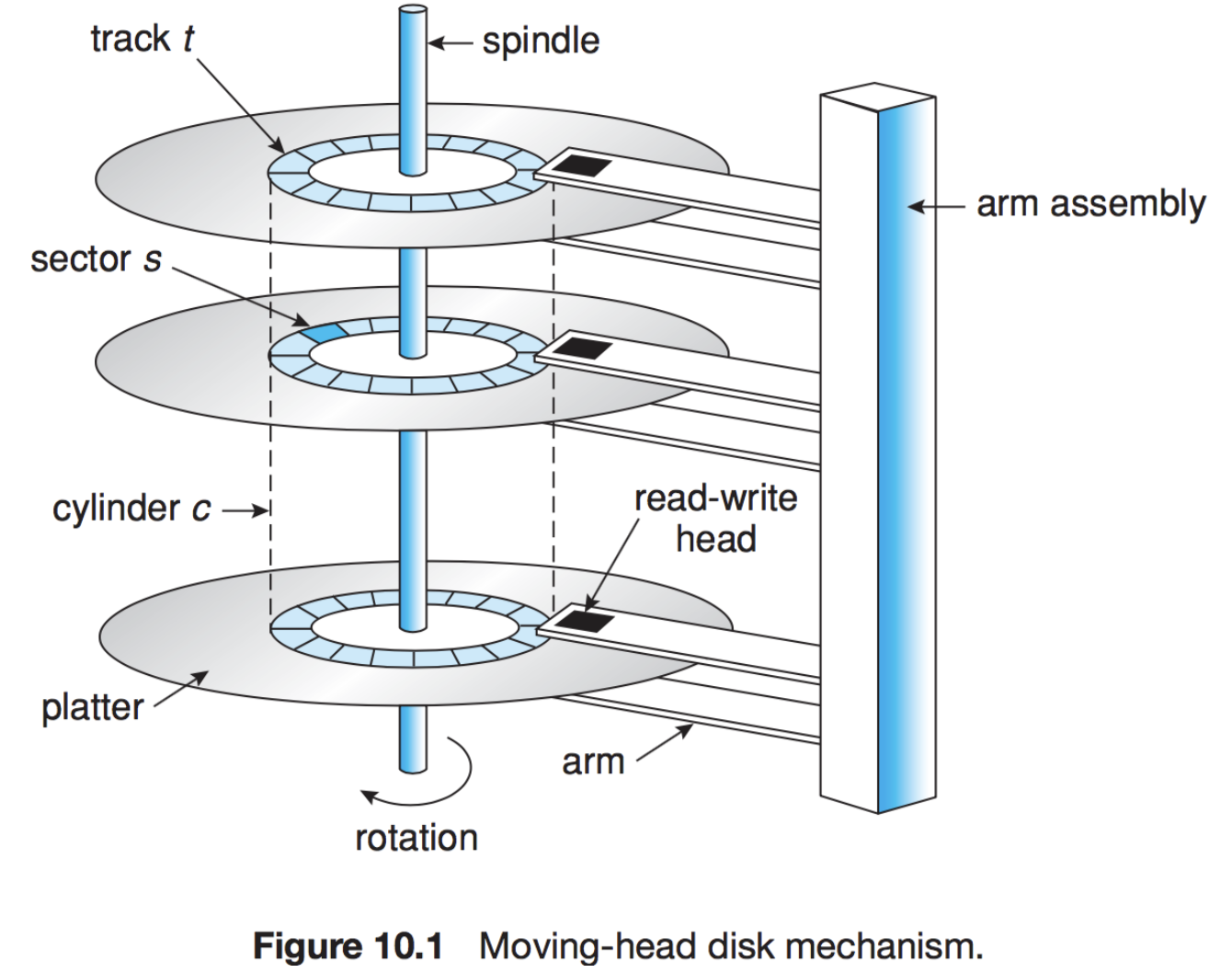
이 판에 작은 블록들이 있고 해당 블록에 arm assembly가 다가가서 데이터를 읽는다. 데이터를 읽고 쓰는 방식은 cpu의 명령에 따라 0과1로 해당 기판의 자성을 변경시켜저장하지 않을까 하는 생각을 합니다.
논리적 환경
물리적 말고 우리가 매일 보는 컴퓨터 환경으로 넘어오게 되면 레코드는 파일안에 저장이 된다. 파일은 다시 블록이라는 고정길이 저장 단위로 저장이 되는데 이 블록이 실제 물리적 디스크에 하나씩 저장이 되는 것이다.
이렇게 되면 아래와 같은 순서도가 그려진다.
레코드라는 데이터는 결국 디스크에 쓰고 읽혀진다.
파일 -> 블록 -> 디스크
기본적으로 블록은 4~8KB로 사용하지만 DBMS는 크기가 다를 때도 있다.
고정길이 레코드
그렇다면 생각을 한번 해보자. 우리가 관계형 데이터베이스를 사용할 때 흔히들 이런 구문으로 테이블을 생성한다.
type instructor = record
ID varchar(5)
name varchar(20)
dept_name varchar(20)
salary numeric(8,2)
endinstructor라는 테이블 == 레코드는 ID, name, dept_name, salary를 n행 (tuple)로 가지는 레코드가 된다. 여기서 각 문자는 1바이트 numeric는 8바이트를 차지한다고 생각하면 한개의 tuple은 53바이트가 된다.
그럼 우리는 4~8KB블록을 사용한다고 했음으로 이 레코드는 4000B/53B이므로 1개의 블록에 약 80개가 조금 안되게 들어가게 되는 것이다.
여기에는 2가지 문제점이 생기게 되는데
- 블록의 크기가 위에처럼 53의 배수가 안되면 마지막이 짤리면서 1개의 tuple을 읽으려할 때 2개의 block을 읽어야하는 문제가 생긴다.
- 삭제를 할 때 특정 위치의 tuple을 삭제한다면 해당 레코드의 해당 tuple위치는 비어있게 된다.

1번 문제는 위의 예시처럼 뒤에 소숫점은 버리고 정수의 개수로만 저장을 하면된다. 2번 문제는 삭제한 레코드의 칸이 비지 않게 매번 삭제때마다 앞으로 데이터를 옮기는 방법이 있다. 이는 ArrayList의 삭제 혹은 삽입의 경우와 유사한데 이러한 상황이 반복된다면 당연히 시간적으로 손해가 많이 일어나게 된다.
이를 위해 삭제 한 부분의 상황을 기록하는 방식을 취하게 된다면 삭제한 곳에 데이터를 넣음으로써 시간을 줄일 수 있게 되는 것이다.

그렇다면 삭제한 부분을 알고있어야 하는 상황이 되는데 이는 파일 헤더를 만듦으로써 해결할 수 있다. 여기에 저장되는 정보에 삭제된 첫번째 record의 위치를 기억하게 하고 다음 삭제된 위치를 link시켜서 기록하게 한다.
이렇게 연결리스트로 삭제된 위치가 기록되게 된다면 새로운 값이 들어올 때 해당 위치에 저장을 하게 되면서 움직이면 시간적 손실을 줄일 수 있다.
